Copyright © 1992 by Annual Reviews. All rights reserved
| Annu. Rev. Astron. Astrophys. 1992. 30:
613-52 Copyright © 1992 by Annual Reviews. All rights reserved |



2.1.1 TECHNIQUES
Various techniques have been devised for automatically
identifying and classifying faint images in digital data.
Galaxy images are usually assumed to be contiguous and
centrally concentrated, and a search for local maxima then
provides a first-cut basis for image detection. To guard
against noise peaks, one imposes a lower limit to the number
of contiguous pixels that appear above a set threshold. To
guard against incompleteness, one sets the threshold as low
as possible. Thus, galaxy counts tend not to be strictly
magnitude-limited, but rather are limited simultaneously in
area and in surface brightness. If the detection area were,
say, 2 arcsec2, and if the threshold in surface brightness
were 3 x 10-3 of the B-band sky background, then
galaxies with measured B = 28.5 could be detected. The magnitude
is then measured in some way that maintains a particular signal-to-noise
ratio, or allows a relatively convenient interpretation
of the results, or has some other desirable attribute.
Isophotal magnitudes are computed by integrating the flux
above a chosen surface brightness threshold; aperture
magnitudes are computed within an area of fixed size; quasi-
total or asymptotic magnitudes attempt to collect close to
all the light; and a number of other schemes have also been
tried (see
Kron 1980b).
Photometry of galaxies is not a well-defined procedure
and requires attention to many technical details, since a
number of systematic errors or biases emerge at very low
signal-to-noise ratio: 1. Small errors in the subtracted sky
can easily dominate the net photometric errors. 2. Crowding
of images becomes a significant problem at faint limits (by
B = 26, the average separation is only 12 arcsec, with many
galaxies overlapping). Software must be able to distinguish
cases of confused images and to account properly for the flux
in the individual components. 3. Ultraviolet images of
nearby spiral galaxies, which will approximate the appearance
of faint galaxies in the U and B bands, show distributed
patches of high surface brightness
(Bohlin et al. 1991).
Thus real images might not conform to the centrally-concentrated,
contiguous idealization of image-detection algorithms. 4. Some effects
are peculiar to isophotes in noisy data. Due to photon shot noise, even
a centrally concentrated image may break up into small islands that
become difficult to reassemble without bias in the derived
fluxes. Moreover, objects will appear artificially bright
because statistically low pixels will be excluded from the
isophotal area. 5. There will be a statistical redistribution of objects
resulting in steeper counts because there are more faint galaxies than
brighter ones and the photometric errors increase with increasing
magnitude. 6. Competing with this effect is increasing incompleteness with
increasing magnitude. 7. A different problem is the
photometric zero-point, which is based on bright stars that
have spectral shapes quite different from those of high-redshift galaxies.
Accurate interpretations of faint galaxy counts should
thus be based on detailed simulations of the selection
function, random errors, and known systematic errors. We
prefer to include these aspects in the model rather than
applying correction factors to the data. In this review, we
adopt this viewpoint by emphasizing the common elements of
observations by independent groups and by plotting
uncorrected data.
2.1.2 BRIGHTER GALAXY COUNTS
Essentially all modern bright galaxy counts are derived
from Schmidt plates, notably the UK Schmidt (see
Heydon-Dumbleton et
al. 1989
and Maddox et al. 1990
for examples) and the Palomar/Oschin Schmidt. The counts of
Sebok (1986)
and Picard (1991)
are illustrative of some of the differences
between surveys. Both used IIIa-F plates with the Schmidt
telescope at Palomar and surveyed contiguous northern regions
at b ~ +50°. Sebok analyzed 4 plates, and Picard 7 plates.
Both made direct calibrations of their photographic
photometry with selected galaxies in their fields and reduced
their results to the Gunn/Thuan r-band system. The star
counts are similar in both studies, yet the galaxy counts,
A(m), are apparently different: over the interval
16.5 < r < 19, Sebok's counts are steeper than Picard's. At
r = 16.5,
This difference may be partly due to the details of the
photometry and its calibration. The measuring machines, the
software, the detectors used for calibration, and the
technique of calibration, were all quite different.
Considering the fundamental limitation of photographic plates
to record faithfully intensity levels over a wide dynamic
range; the possibility of the data being affected by
scattered light in the respective microdensitometers; and the
wide range of galaxy profile shapes, even direct calibration
of integrated magnitudes on photographic plates may not
always be reliable.
Counts of brighter galaxies in the blue band have been
studied by many more investigators. The work of
Maddox et al. (1990)
is important because the area covered is 4300
deg2, far larger than any other photometric survey. Since
other surveys lie within the
Maddox et al. (1990)
region, there is the opportunity to compare photometry on a galaxy-
by-galaxy basis: differences in the zero points for each
common field are of order 0.15 mag
(Maddox et al. 1990).
Maddox et al. (1990)
called attention to the steeper
slope of their counts,
2.1.3 FAINTER GALAXY COUNTS
Figure 1 shows the differential counts log
A(m) (number
per deg2 per mag) for surveys in the blue, red, and near-
infrared bands, transformed where necessary to the adopted
standards of photographic bJ, Gunn r, and
K, according to information presented in the original papers. Some
differences do appear between different investigators, but
the overall agreement is obvious, and we do not distinguish
between the separate surveys in Figure 1;
sources are given in the figure caption. To prevent excessive crowding of the
points, in general we have omitted photographic photometry
for bJ and r in the intermediate range of
magnitudes. We have plotted data only brighter than conservative limits
where the statistical noise in the sky background is
comparable to the flux itself (and beyond which the
corrections for incompleteness become large).
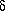 logA =
0.42, and at r = 19, logA = 0.08, in the
sense: Picard (north) - Sebok. The difference between these
two northern fields, which are separated by about 60 degrees,
is in fact greater than the difference between Picard's
northern and southern fields (logA ~ 0.15). The areas and
depths are large enough that the effect of large-scale
structure at the level of 1 s is expected to be less than
logA = ± 0.04
(S. M. Kent, private communication).
logA / m, in the general range
17 < B < 19, than predicted by
Ellis's (1987)
no-evolution model. In fact, the steep slope in this region is
characteristic of a number of such studies, e.g.
Butcher and Oemler
(1985),
Stevenson, Shanks, and
Fong (1986), and
Heydon-Dumbleton et
al. (1989).
Butcher and Oemler
(1985)
presented a summary of the
Kirshner, Oemler, and
Schechter (1978) and
Kirshner et al. (1983)
field-galaxy counts and color distributions.
Stevenson, Shanks, and
Fong (1986)
presented data from 17 Schmidt fields covering 355 deg2.
Heydon-Dumbleton et
al. (1989)
surveyed 100 deg2, and there
are over 3000 galaxies in their survey in the interval
17.5 < B < 18.5. All of these surveys are characterized by a
slope that is as steep as that of Maddox et al. for B < 19.
Even more extreme are Sebok's counts, which reach deeper than
the blue counts discussed so far, and yet are almost as steep
as the Euclidean case logA/ m = 0.6 up to r = 18, where
confusion with stars begins to become important. We will
return to this result in Section 3.3.
logA =
0.42, and at r = 19, logA = 0.08, in the
sense: Picard (north) - Sebok. The difference between these
two northern fields, which are separated by about 60 degrees,
is in fact greater than the difference between Picard's
northern and southern fields (logA ~ 0.15). The areas and
depths are large enough that the effect of large-scale
structure at the level of 1 s is expected to be less than
logA = ± 0.04
(S. M. Kent, private communication).
logA / m, in the general range
17 < B < 19, than predicted by
Ellis's (1987)
no-evolution model. In fact, the steep slope in this region is
characteristic of a number of such studies, e.g.
Butcher and Oemler
(1985),
Stevenson, Shanks, and
Fong (1986), and
Heydon-Dumbleton et
al. (1989).
Butcher and Oemler
(1985)
presented a summary of the
Kirshner, Oemler, and
Schechter (1978) and
Kirshner et al. (1983)
field-galaxy counts and color distributions.
Stevenson, Shanks, and
Fong (1986)
presented data from 17 Schmidt fields covering 355 deg2.
Heydon-Dumbleton et
al. (1989)
surveyed 100 deg2, and there
are over 3000 galaxies in their survey in the interval
17.5 < B < 18.5. All of these surveys are characterized by a
slope that is as steep as that of Maddox et al. for B < 19.
Even more extreme are Sebok's counts, which reach deeper than
the blue counts discussed so far, and yet are almost as steep
as the Euclidean case logA/ m = 0.6 up to r = 18, where
confusion with stars begins to become important. We will
return to this result in Section 3.3.
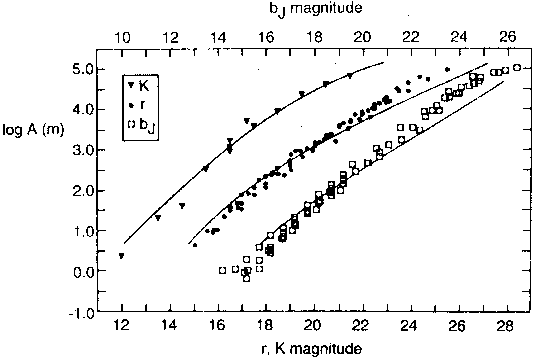
Figure 1. Differential galaxy counts A(m) in number per
square degree per magnitude in the blue (bJ), red
(Gunn r), and near-infrared (K) bands. The magnitude scale
for the bJ counts is at the top. To cover the greatest
range in magnitude, the plot shows bright photographic surveys and
faint CCD surveys. Sources for the blue counts:
Butcher and Oemler
(1985);
Stevenson et al. (1986);
Ciardullo (1987);
Heydon-Dumbleton et
al. (1989);
Maddox et al. (1990);
Jones et al. (1991);
Tyson (1988);
Metcalfe et al. (1991);
Neuschaefer et al. 1991;
Lilly, Cowie, and
Gardner (1991).
Sources for the red counts:
Stevenson et al. (1986);
Sebok (1986);
Picard (1991);
Hall and Mackay (1984);
Yee, Green, and
Stockman (1986);
Tyson (1988);
Metcalfe et al. (1991).
Sources for the K-band counts:
Mobasher et al. (1986);
Broadhurst, Ellis, and
Glazebrook (1992);
Cowie et al. (1992).
The curves give the predicted counts for the no-evolution model
discussed in the text, all sharing a common normalization.