


3.2 Random Errors
In contrast to systematic errors, random errors may be handled by the theory of statistics. These uncertainties may arise from instrumental imprecisions, and/or, from the inherent statistical nature of the phenomena being observed. Statistically, both are treated in the same manner as uncertainties arising from the finite sampling of an infinite population of events. The measurement process, as we have suggested, is a sampling process much like an opinion poll. The experimenter attempts to determine the parameters of a population or distribution too large to measure in its entirety by taking a random sample of finite size and using the sample parameters as an estimate of the true values.
This point of view is most easily seen in measurements of statistical processes, for example, radioactive decay, proton-proton scattering, etc. These processes are all governed by the probabilistic laws of quantum mechanics, so that the number of disintegrations or scatterings in a given time period is a random variable. What is usually of interest in these processes is the mean of the theoretical probability distribution. When a measurement of the number of decays or scatterings per unit time is made, a sample from this distribution is taken, i.e., the variable x takes on a value x1. Repeated measurements can be made to obtain x2, x3, etc. This, of course, is equivalent to tossing a coin or throwing a pair of dice and recording the result. From these data, the experimenter may estimate the value of the mean. Since the sample is finite, however, there is an uncertainty on the estimate and this represents our measurement error. Errors arising from the measurement of inherently random processes are called statistical errors.
Now consider the measurement of a quantity such as the length of a table or the voltage between two electrodes. Here the quantities of interest are well-defined numbers and not random variables. How then do these processes fit into the view of measurement as a sampling process? What distribution is being sampled?
To take an example, consider an experiment such as the measurement
of the length of a table with say, a simple folding ruler. Let us make
a set of repeated measurements reading the ruler as accurately as
possible. (The reader can try this himself!). It will then be noticed
that the values fluctuate about and indeed, if we plot the frequency
of the results in the form of a histogram, we see the outlines of a
definite distribution beginning to take form. The differing values are
the result of many small factors which are not controlled by the
experimenter and which may change from one measurement to the next,
for example, play in the mechanical joints, contractions and
expansions due to temperature changes, failure of the experimenter to
place the zero at exactly the same point each time, etc. These are all
sources of instrumental error, where the term instrument
also includes
the observer! The more these factors are taken under control, of
course, the smaller will be the magnitude of the fluctuations. The
instrument is then said to be more precise. In the limit of an ideal,
perfect instrument, the distribution then becomes a
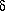 -function
centered at the true value of the measured quantity. In reality, of
course, such is never the case.
-function
centered at the true value of the measured quantity. In reality, of
course, such is never the case.
The measurement of a fixed quantity, therefore, involves taking a sample from an abstract, theoretical distribution determined by the imprecisions of the instrument. In almost all cases of instrumental errors, it can be argued that the distribution is Gaussian. Assuming no systematic error, the mean of the Gaussian should then be equal to the true value of the quantity being measured and the standard deviation proportional to the precision of the instrument.
Let us now see how sampled data are used to estimate the true parameters.