Copyright © 2002 by Annual Reviews. All rights reserved
| Annu. Rev. Astron. Astrophys. 2002. 40:
539-577 Copyright © 2002 by Annual Reviews. All rights reserved |



3.1. Optically-based Cluster Surveys
Abell (1958) provided the first extensive, statistically complete sample of galaxy clusters. Based on pure visual inspection, clusters were identified as enhancements in the galaxy surface density on Palomar Observatory Sky Survey (POSS) plates, by requiring that at least 50 galaxies were contained within a metric radius RA = 3h50-1 Mpc and a predefined magnitude range. Clusters were characterized by their richness and estimated distance. The Abell catalog has been for decades the prime source for detailed studies of individual clusters and for characterizing the large scale distribution of matter in the nearby Universe. The sample was later extended to the Southern hemisphere by Corwin and Olowin (Abell, Corwin & Olowin, 1989) by using UK Schmidt survey plates. Another comprehensive cluster catalog was compiled by Zwicky and collaborators (Zwicky et al. 1966), who extended the analysis to poorer clusters using criteria less strict than Abell's in defining galaxy overdensities.
Several variations of the Abell criteria defining clusters were used in an automated and objective fashion when digitized optical plates became available. The Edinburgh-Durham Southern Galaxy Catalog, constructed from the COSMOS scans of UK Schmidt plates around the Southern Galactic Pole, was used to compile the first machine-based cluster catalog (Lumsden et al. 1992). In a similar effort, the Automatic Plate Measuring machine galaxy catalog was used to build a sample of ~ 1000 clusters (Maddox et al. 1990, Dalton et al. 1997).
Projection effects in the selection of cluster candidates have been much debated. Filamentary structures and small groups along the line of sight can mimic a moderately rich cluster when projected onto the plane of the sky. In addition, the background galaxy distribution against which two dimensional overdensities are selected, is far from uniform. As a result, the background subtraction process can produce spurious low-richness clusters during searches for clusters in galaxy catalogs. N-body simulations have been extensively used to build mock galaxy catalogs from which the completeness and spurious fraction of Abell-like samples of clusters can be assessed (e.g. van Haarlem et al. 1997). All-sky, X-ray selected surveys have significantly alleviated these problems and fueled significant progress in this field as discussed below.
Optical plate material deeper than the POSS was successfully employed
to search for more distant clusters with purely visual techniques
(Kristian et al. 1978,
Couch et al. 1991,
Gunn et al. 1986).
By using red-sensitive plates, Gunn and collaborators were able
to find clusters out to
z 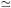 0.9. These
searches became much more effective with the advent of CCD imaging.
Postman et al. (1996)
were the first to carry out a V&I-band survey over 5 deg2
(the Palomar Distant Cluster Survey, PDCS) and to compile a sample of 79
cluster candidates using a matched-filter algorithm. This technique
enhances the contrast of galaxy overdensities at a given position,
utilizing prior knowledge of the luminosity profile typical of galaxy
clusters.
Olsen et al. (1999)
used a similar algorithm to select a
sample of 35 distant cluster candidates from the ESO Imaging Survey
I-band data. A simple and equally effective counts-in-cell method was
used by
Lidman & Peterson
(1996)
to select a sample of 104 distant
cluster candidates over 13 deg2. All these surveys, by using
relatively deep I-band data, are sensitive to rich clusters out to
z ~ 1. A detailed spectroscopic study of one of the most
distant clusters at z = 0.89 discovered in this way is reported in
Lubin et al. (2000).
0.9. These
searches became much more effective with the advent of CCD imaging.
Postman et al. (1996)
were the first to carry out a V&I-band survey over 5 deg2
(the Palomar Distant Cluster Survey, PDCS) and to compile a sample of 79
cluster candidates using a matched-filter algorithm. This technique
enhances the contrast of galaxy overdensities at a given position,
utilizing prior knowledge of the luminosity profile typical of galaxy
clusters.
Olsen et al. (1999)
used a similar algorithm to select a
sample of 35 distant cluster candidates from the ESO Imaging Survey
I-band data. A simple and equally effective counts-in-cell method was
used by
Lidman & Peterson
(1996)
to select a sample of 104 distant
cluster candidates over 13 deg2. All these surveys, by using
relatively deep I-band data, are sensitive to rich clusters out to
z ~ 1. A detailed spectroscopic study of one of the most
distant clusters at z = 0.89 discovered in this way is reported in
Lubin et al. (2000).
Dalcanton (1996) proposed another method of optical selection of clusters, in which drift scan imaging data from relatively small telescopes is used to detect clusters as positive surface brightness fluctuations in the background sky. Gonzales et al. (2001) used this technique to build a sample of ~ 1000 cluster candidates over 130 deg2. Spectroscopic follow-up observations will assess the efficiency of this technique.
The advantage of carrying out automated searches based on well-defined selection criteria (e.g. Postman et al. 1996) is that the survey selection function can be computed, thus enabling meaningful statistical studies of the cluster population. For example, one can quantify the probability of detecting a galaxy cluster as a function of redshift for a given set of other parameters, such as galaxy luminosity function, luminosity profile, luminosity and color evolution of cluster galaxies, and field galaxy number counts. A comprehensive report on the performance of different cluster detection algorithms applied to two-dimensional projected distributions can be found in Kim et al. (2002).
The success rate of finding real bound systems in optical surveys is
generally relatively high at low redshift (z < 0.3,
Holden et al. 1999),
but it degrades rapidly at higher redshifts, particularly
if only one passband is used, as the field galaxy population
overwhelms galaxy overdensities associated with clusters. The simplest
way to counteract this effect is to observe in the near-infrared bands
(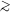 1µm). The cores of galaxy clusters are dominated by
red, early-type galaxies at least out to
z 1.3 for which the
dimming effect of the K-correction is particularly severe. In
addition, the number counts of the field galaxy population are flatter
in the near-IR bands than in the optical. Thus, by moving to
z, J, H, K
bands, one can progressively compensate the strong K-correction and
enhance the contrast of (red) cluster galaxies against the background
(blue) galaxy distribution. An even more effective way to enhance the
contrast of distant clusters is to use some color information, so that
only overdensities of galaxies with peculiar red colors can be
selected from the field. With a set of two or three broad band
filters, which sample the rest frame UV and optical light at different
redshifts, one can separate out early type galaxies which dominate
cluster cores from the late type galaxy population in the field. The
position of the cluster red sequence in color-magnitude diagrams,
and red clumps in color-color diagrams can also be used to provide
an accurate estimate of the cluster redshift, by modeling the
relatively simple evolutionary history of early-type galaxies.
1µm). The cores of galaxy clusters are dominated by
red, early-type galaxies at least out to
z 1.3 for which the
dimming effect of the K-correction is particularly severe. In
addition, the number counts of the field galaxy population are flatter
in the near-IR bands than in the optical. Thus, by moving to
z, J, H, K
bands, one can progressively compensate the strong K-correction and
enhance the contrast of (red) cluster galaxies against the background
(blue) galaxy distribution. An even more effective way to enhance the
contrast of distant clusters is to use some color information, so that
only overdensities of galaxies with peculiar red colors can be
selected from the field. With a set of two or three broad band
filters, which sample the rest frame UV and optical light at different
redshifts, one can separate out early type galaxies which dominate
cluster cores from the late type galaxy population in the field. The
position of the cluster red sequence in color-magnitude diagrams,
and red clumps in color-color diagrams can also be used to provide
an accurate estimate of the cluster redshift, by modeling the
relatively simple evolutionary history of early-type galaxies.
The effectiveness of this method was clearly demonstrated by Stanford et al. (1997), who found a significant overdensity of red galaxies with J - K and I - K colors typical of z > 1 ellipticals and were able to spectroscopically confirm this system as a cluster at z = 1.27 (c.f. see also Dickinson 1997). With a similar color enhancement technique and follow-up spectroscopy, Rosati et al. (1999) confirmed the existence of an X-ray selected cluster at z = 1.26. Gladders & Yee (2000) applied the same technique in a systematic fashion to carry out a large area survey in R and z bands (the Red Sequence Survey), which is currently underway and promises to unveil rare, very massive clusters out to z ~ 1.
By increasing the number of observed passbands one can further increase the efficiency of cluster selection and the accuracy of their estimated redshifts. In this respect, a significant step forward in mapping clusters in the local Universe will be made with the five-band photometry provided by the Sloan Digital Sky Survey (York et al. 2000). The data will allow clusters to be efficiently selected with photometric redshift techniques, and will ultimately allow hundreds of clusters to be searched directly in redshift space. The next generation of wide field (> 100 deg2) deep multicolor surveys in the optical and especially the near-infrared will powerfully enhance the search for distant clusters.