


2.2. Cosmology
Let us imagine for the sake of this section, that `cosmology' is synonymous with the search for the values of a number of parameters which describe the properties of the Universe.
Figure 3 appears to show that
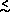 l
350,
l
350,
avoiding any detailed statistical arguments here, and just sticking to
round numbers (and remembering that there are tight upper limits at
higher values of l, so that the power spectrum really does have
to come down again). Since the standard
CDM model has the main peak at l
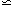 220, and it is pushed to
smaller scales in open models, then it is hard for
220, and it is pushed to
smaller scales in open models, then it is hard for
 tot to be less than,
say, 0.3. Rigorous studies (e.g.
[34])
arrive at similar conclusions.
tot to be less than,
say, 0.3. Rigorous studies (e.g.
[34])
arrive at similar conclusions.
The height of the peak is somewhat higher than predicted for sCDM, but
entirely consistent with several variants
(2)
Currently popular models with a cosmological
constant tend to provide perfectly good fits to the CMB (in addition to
large-scale clustering of galaxies and the supernovae results
[35]). The curve
plotted in Figure 3, shows one such
flat model with 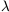 = 0.6
and a Hubble constant of 70 km s-1 Mpc-1
[36].
= 0.6
and a Hubble constant of 70 km s-1 Mpc-1
[36].
Since the height of the first peak depends on a combination of
parameters, then exactly what quantities are constrained
depends on the parameter space being searched, as well as on the choice
of additional constraints. Currently it is possible to constrain
the matter density MM to ~ ± 0.1 from the peak height,
but that depends sensitively on the assumptions used. All this is
expected to change as better data come in.
The basic thing to take away here is that models with adiabatic-type (i.e. where you perturb the matter and radiation at the same time in order to keep the entropy fixed) perturbations have the right kind of character. On the other hand isocurvature-type models (where the matter and radiation get equal and opposite perturbations, so that the local curvature is unperturbed) tend to look poor - generically they have a `shoulder' rather than a first peak, and then the highest peak is at much smaller scale (see e.g. [37]). While there are some loop-holes, it seems difficult to get isocurvature models to fit the current data.
2 Rather than vanilla CDM
you can have a slightly different flavour, or some chocolate sprinkles, or
maybe a cherry on top. Back.