


Astronomers can accurately measure the galaxy positions on the sky. Unfortunately, it is not possible to have the same accuracy for the radial distance of each object. Different distance estimators are used in astronomy (see, for example, Ref. 1 for a review). For the luminosity selection effects one has to use the luminosity distance Dl, for the angular selection effects the angular diameter distance Da, and in order to describe spatial clustering the comoving distance r is used. All these distances can be derived from the cosmological redshift of the galaxy zcos. Distances however depend on the adopted cosmological model and the value of its parameters. For nearby galaxies, the Hubble law states that czcos = H0r where H0 is the present value of the Hubble parameter. Recent measurements [2] provide a value of H0 = 72±8 km s-1 Mpc-1. As space is curved, for more distant galaxies the distance-redshift relation is not linear any more, and different distances differ. We illustrate this in Fig. 1, where the different cosmological distances are given for the presently popular 'concordance model'. The statistics describing spatial clustering obviously depend on the adopted distance definitions, and thus on the prior cosmological model. This should be kept in mind, as these statistics are frequently used to estimate the 'true' parameters of the cosmological model.
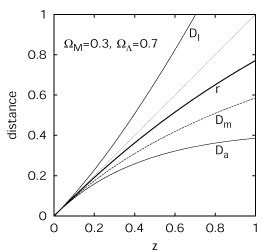 |
Figure 1. Different distance measures for a currently popular 'concordance' model universe. Here Dl is the luminosity distance, r is the comoving distance, Dm is the usually used Mattig distance (not defined for this model), and Da is the angular diameter distance. All distances are given in the units of the Hubble length c/H0. |
It is important to mention that the true cosmological redshift is not a measurable quantity since what we really are able to measure for each galaxy is a quantity z satisfying the relation cz = czcos + vpec where vpec is the line-of-sight peculiar velocity. Peculiar velocities create a distorted version of the galaxy distribution - namely the redshift space -, as opposed to the real space where galaxies lie at their real positions. Distortions are more severe within the high density regions where effects like the Fingers-of-God - elongated structures along the line-of-sight - are the most evident consequence [3]. In next sections we will discuss how this distortions affect the statistical clustering measures.