


6.2. The clustering of Lyman-break galaxies
The high efficiency of the Lyman-break technique and the relatively
narrow range of
redshifts/cosmic time that it probes make angular clustering a
particularly economic
means to study large-scale structure at high redshifts, once the
redshift distribution
N(z) of the galaxy candidates has been measured. Not only is one
free from securing
a complete spectroscopic follow-up of all the candidates, but the
systematics due to
selection effects are easier to handle than those that affect studies of
spatial clustering
using the full redshift information. Knowing N(z), the real-space
correlation function can
be accurately derived from the angular one through the Limber transform
(Peebles 1980;
Efstathiou et al. 1991).
It turns out that the inversion of the
w(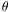 ) is rather insensitive to
the still relatively large uncertainties on the angular function, and
the spatial correlation
length is much more tightly constrained than this
(Giavalisco et al. 1998).
) is rather insensitive to
the still relatively large uncertainties on the angular function, and
the spatial correlation
length is much more tightly constrained than this
(Giavalisco et al. 1998).
The angular correlation function
w() is defined in terms
of the excess probability over
the random (poisson) distribution of finding a companion in an angular
shell of size d placed at an angular separation
from a selected galaxy, given
the surface density of sources N
(Peebles 1980):
placed at an angular separation
from a selected galaxy, given
the surface density of sources N
(Peebles 1980):
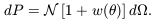
| (2) |
We used the 5 largest and deepest fields of our survey to produce a
weighted average angular correlation function
w() of LBGs. Figure 10a
shows the data points, their error
bars and the fitted power-law model.
We subsequently inverted the angular correlation function using the
Limber transform
and the observed redshift distribution N(z) to derive the
parameters of the spatial
correlation function at the epoch of observations, namely the
correlation length r0 and the
slope 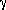 = 1 +
= 1 +
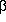 , under the
assumption of the power-law model
, under the
assumption of the power-law model
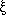 (r) =
(r/r0)-.
(r) =
(r/r0)-.
To estimate confidence intervals on the parameters
and
r0, we used montecarlo
simulations. Figure 10b shows the distribution
of values of r0 and
obtained from the
simulations. As mentioned above, the correlation length turns out to be
much more
tightly constrained than the individual parameters of the angular
correlation function, with a typical fractional error of
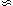 30% at the
1-
30% at the
1- level. As our fiducial
measure and error
bar we adopt the median of the distributions of the simulations and its
corresponding
68% confidence intervals. These are r0 =
2.1+0.4-0.5 and r0 =
3.3+0.7-0.6 h-1 Mpc (comoving
coordinates) for q0 = 0.5 and q0 =
0.1, respectively, for the correlation length, and
=
1.98+0.32-0.28 for the slope.
level. As our fiducial
measure and error
bar we adopt the median of the distributions of the simulations and its
corresponding
68% confidence intervals. These are r0 =
2.1+0.4-0.5 and r0 =
3.3+0.7-0.6 h-1 Mpc (comoving
coordinates) for q0 = 0.5 and q0 =
0.1, respectively, for the correlation length, and
=
1.98+0.32-0.28 for the slope.

|
Figure 10. a) Weighted average angular
correlation function of LBGs. The filled points are
from the PB estimator, the open points from the LS one. The error bars
are shown on the top
of the figure. The continuous line is the best-fit power law to the PB
data points, the dotted line
is the fit to the LS. The thick horizontal continuous segment on the x
axis marks the angular
range over which the we computed the fits. b) The histogram of the
correlation length r0 (lower panel) and of the slope
|
We can estimate the bias of these galaxies by comparing their
correlation function
g
to the correlation function of the mass
m:
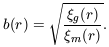
| (3) |
Although (as eq. 3 shows) the bias is in principle a function of scale,
our constraint on the power-law exponent
is relatively
weak and we can only estimate a "typical" value
of the bias over the scales of a few Mpc which are probed here. In
practice, we use
the ratio of the correlation length of the LBGs to that of
m(r)
predicted by the CDM
theory to compute the bias, which is therefore relative to r = 1
h-1 Mpc. Using a CDM
power-spectrum with shape parameter
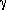 * = 0.25, claimed to fit the
shape of the local large-scale structure very well
(Peacock 1997),
and normalization of
Eke, Cole, & Frenk
(1996),
we estimate b ~ 4.5 (1.5) for q0 = 0.5
(0.1). Choosing * = 0.20
results in b ~ 5 (1.5), while adopting the normalization of
White, Efstathiou & Frenk (1993)
results in b ~ 4 (1).
* = 0.25, claimed to fit the
shape of the local large-scale structure very well
(Peacock 1997),
and normalization of
Eke, Cole, & Frenk
(1996),
we estimate b ~ 4.5 (1.5) for q0 = 0.5
(0.1). Choosing * = 0.20
results in b ~ 5 (1.5), while adopting the normalization of
White, Efstathiou & Frenk (1993)
results in b ~ 4 (1).
Very interestingly, the correlation function of the Lyman-break galaxies
has a slope
that is comparable to or steeper than that measured at intermediate and
low redshifts.
The evolution of the slope of the correlation function of the mass (or,
equivalently, that
of the power spectrum at small scales) has a pronounced dependence on
. For a CDM-like
power spectrum, it depends very weakly on the shape parameter
* and, for flat
models, on the normalization. As eqn. (3) shows, the slope of
g(r)
differs from that of
m(r)
because of the dependence of the bias parameter b(r) with the
spatial scale. The
form of b(r), its dependence on galaxy properties and how it
evolves with redshift are
still subjects of discussion (e.g.,
Mann, Peacock &
Heavens 1998;
Bagla 1997).
If the scale dependence of b(r) for the LBGs over the spatial scales
probed by our correlation
analysis, namely 1 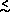 r 10
h-1 Mpc, is similar to that of the local galaxies,
then our
measures of are
inconsistent with
m(r)
from the CDM theory if =
1. With our choice
of * = 0.25 we found
m =
1.25 (over the range 1 < r < 10 h-1 Mpc),
independently of
the normalization. As mentioned above, the dependence on
* is very weak. If
* = 0.1
then m
= 0.98, while if * = 0.6, then
m =
1.14. Thus, the observed slope rules out
the steepest CDM slope
(m =
1.25) is ruled at the 99.95% confidence level. Open CDM
models with the same parameters as above produce slopes in the range 1.6
< m < 2.1 (in
open models the slope of
m(r)
has a more pronounced dependence on the normalization),
which are all consistent with our data.
r 10
h-1 Mpc, is similar to that of the local galaxies,
then our
measures of are
inconsistent with
m(r)
from the CDM theory if =
1. With our choice
of * = 0.25 we found
m =
1.25 (over the range 1 < r < 10 h-1 Mpc),
independently of
the normalization. As mentioned above, the dependence on
* is very weak. If
* = 0.1
then m
= 0.98, while if * = 0.6, then
m =
1.14. Thus, the observed slope rules out
the steepest CDM slope
(m =
1.25) is ruled at the 99.95% confidence level. Open CDM
models with the same parameters as above produce slopes in the range 1.6
< m < 2.1 (in
open models the slope of
m(r)
has a more pronounced dependence on the normalization),
which are all consistent with our data.
The above computations assume a bias constant with spatial scale. We stress,
however, that the evolution of the slope of the correlation function is
useful for constraining
cosmological models only if the dependence of the bias with the spatial
scale and its
evolution with redshift are known. The function b(r) also depends
on the properties of the
halos, which further complicates the interpretation of the data because
of the difficulty of
establishing an evolutionary sequence between the systems observed at
high redshifts and the local galaxies.
Bagla's (1997)
N-body simulations seem to suggest that the bias will
not be strongly scale-dependent - his b(r) for M > 2 x
1012 M halos at z = 0 in
standard CDM has a power-law slope of only ~ -0.18 - and if b(r)
for Lyman-break galaxies
is similarly flat, our conclusions about the slope would not be
importantly changed. But
until more is known about the scale-dependence of the bias they will
remain speculative.
halos at z = 0 in
standard CDM has a power-law slope of only ~ -0.18 - and if b(r)
for Lyman-break galaxies
is similarly flat, our conclusions about the slope would not be
importantly changed. But
until more is known about the scale-dependence of the bias they will
remain speculative.