

High Energy Physics
(HEP) is well known for using
very sophisticated detectors,
status of the art computers, ultra-fast data acquisition systems,
and very detailed (Monte Carlo) simulations. One might imagine
that a similar level of refinement
could be found in its analysis tools, on the trail of
the progress in probability theory and statistics of the
past half century. Quite the contrary! As pointed out by
the downhearted Zech
[1],
``some decades ago physicists were usually well educated
in basic statistics in contrast to their colleagues in social and
medical sciences. Today the situation is almost reversed.
Very sophisticated methods are used in these disciplines, whereas
in particle physics standard analysis tools available in many program
packages seem to make knowledge of statistics obsolete. This leads
to strange habits, like the determination of a r.m.s. of a sample
through a fit to a Gaussian. More severe are a widely spread
ignorance about the (lack of) significance of
 2
tests with a large number of bins and missing experience
with unfolding methods''. In my opinion, the main reason
for this cultural gap is that statistics and probability are not given
sufficient importance in the student curricula: ad hoc formulae
are provided in laboratory courses to report the ``errors'' of measurements;
the few regular lectures on ``statistics'' usually mix up
descriptive statistics, probability theory and
inferential statistics.
This leaves a lot of freedom for personal interpretations of the
subject (nothing to do with subjective probability!).
Of equal significance is the fact that
the disturbing catalog of inconsistencies
[2]
of ``conventional'' (1)
statistics helps to give the impression that this subject is matter of
initiates and local gurus, rather than a scientific
discipline (2) .
The result is that standard knowledge of statistics at
the end of the University curriculum is insufficient and confused,
as widely recognized. Typical effects of this (dis-)education are the
``Gaussian syndrome''
(3)
(from which follows the uncritical use of the rule of combining results,
weighing them with inverse of the ``error'' squared
(4) ,
or the habit of calling 2
any sum of squared differences between fitted curves and data points,
and to use it as if it were a
2),
the abused ``
2
tests with a large number of bins and missing experience
with unfolding methods''. In my opinion, the main reason
for this cultural gap is that statistics and probability are not given
sufficient importance in the student curricula: ad hoc formulae
are provided in laboratory courses to report the ``errors'' of measurements;
the few regular lectures on ``statistics'' usually mix up
descriptive statistics, probability theory and
inferential statistics.
This leaves a lot of freedom for personal interpretations of the
subject (nothing to do with subjective probability!).
Of equal significance is the fact that
the disturbing catalog of inconsistencies
[2]
of ``conventional'' (1)
statistics helps to give the impression that this subject is matter of
initiates and local gurus, rather than a scientific
discipline (2) .
The result is that standard knowledge of statistics at
the end of the University curriculum is insufficient and confused,
as widely recognized. Typical effects of this (dis-)education are the
``Gaussian syndrome''
(3)
(from which follows the uncritical use of the rule of combining results,
weighing them with inverse of the ``error'' squared
(4) ,
or the habit of calling 2
any sum of squared differences between fitted curves and data points,
and to use it as if it were a
2),
the abused ``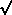 n rule''
to evaluate ``errors'' of counting experiments
(5)
and the reluctance to take into account correlations
(6) ,
just to remain at a very basic level.
n rule''
to evaluate ``errors'' of counting experiments
(5)
and the reluctance to take into account correlations
(6) ,
just to remain at a very basic level.
I don't think that researchers in medical science or in biology have a better statistics education than physicists. On the contrary, their usually scant knowledge of the subject forces them to collaborate with professional statisticians, and this is the reason why statistics journals contain plenty of papers in which sophisticated methods are developed to solve complicated problems in the aforementioned fields. Physicists, especially in HEP, tend to be more autonomous, because of their skills in mathematics and computing, plus of a good dose of intuition. But one has to admit that it is rather unlikely that a physicist, in a constant hurry to publish results before anybody else, can reinvent methods which have been reached by others after years of work and discussion. Even those physicists who are considered experts in statistics usually read books and papers written and refereed by other physicists. The HEP community remains, therefore, isolated with respect to the mainstream of research in probability and statistics.
In this paper I will not try to review all possible methods used in HEP, nor to make a detailed comparison between conventional and Bayesian solutions to solve the same problems. Those interested in this kind of statistical and historical study are recommended to look at the HEP databases and electronic archives [5]. I think that the participants in this workshop are more interested in learning about the attitude of HEP physicists towards the fundamental aspects of probability, in which framework they make uncertainty statements, how subjective probability is perceived, and so on. The intention here will be, finally, to contribute to the debate around the question ``Why isn't everybody a Bayesian'' [2], recently turned into ``Why isn't every physicist a Bayesian'' [6]. The theses which I will try to defend are:
Some of the points sketched quickly in this paper are discussed in detail in lecture notes [7] based on several seminars and minicourses given over the past years. These notes also contain plenty of general and HEP inspired applications.
1 I prefer to call the frequentist approach ``conventional'' rather than ``classical''. Back.
2 Who can have failed to experience endless discussions about trivial statistical problems, the solution of which was finally accepted just because of the (scientific or, more often, political) authority of somebody, rather than because of the strength of the logical arguments? Back.
3 I know a senior physicist who used to teach students that standard deviation is meaningful only for the Gaussian, and that it is ``defined'' as half of the interval around the average which contains 68% of the events! More common is the evaluation of the standard deviation of a data sample fitting a Gaussian to the data histogram (see also the previous quotation of Zech [1]), even in those cases in which the histogram has nothing to do with a Gaussian. The most absurd case I have heard of is that of someone fitting a Gaussian to a histogram exhibiting a flat shape (and having good reasons for being considered to come from coming from a uniform distribution) to find the resolution of a silicon strip detector!. Back.
4 For instance, the 1998 issue of the Review of Particle Physics [3] includes an example based on this kind of mistake with the intention to show that ``the Bayesian methodology ...is not appropriate for the objective presentation of experimental data'' (section 29.6.2, pag. 175). Back.
5 Who has never come across somebody
calculating the ``error'' on the efficiency
 = n / N, using
the standard ``error propagation'' starting from
n
and N ?
Back.
= n / N, using
the standard ``error propagation'' starting from
n
and N ?
Back.
6 In the past, the correlation matrix was for many HEP physicists ``that mysterious list of numbers printed out by MINUIT'' (MINUIT [4] is the minimization/fitting package mostly used in HEP), but at least some cared about understanding what those numbers meant and how to use them in further analysis. Currently - I agree with Zech [1] - the situation has worsened: although many people do take into account correlations, especially in combined analysis of crucial Standard Model parameters, the interactive packages, which display only standard deviations of fitted parameters, tend to ``hide'' the existence of correlations to average users. Back.