


In fairly recent history, cosmological data sets were sparse and
incomplete, and the statistical methods deployed to analyse them
were crude. Second-order statistics, such as P(k) and
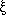 (r),
are blunt instruments that throw away the fine details of the
delicate pattern of cosmic structure. These details lie in the
distribution of Fourier phases to which second-order statistics
are blind. It would not do justice to massively improved data if
effort were directed only to better estimates of these quantities.
Moreover, as we have shown, phase information provides a unique
fingerprint of gravitational instability developed from Gaussian
initial conditions (which have maximal phase entropy). Methods
such as those described above can therefore be used to test this
standard paradigm for structure formation. They can also furnish
direct tests of the presence of initial non-Gaussianity
[Ferreira et al. 1998,
Pando et al. 1998,
Bromley & Tegmark 1999].
(r),
are blunt instruments that throw away the fine details of the
delicate pattern of cosmic structure. These details lie in the
distribution of Fourier phases to which second-order statistics
are blind. It would not do justice to massively improved data if
effort were directed only to better estimates of these quantities.
Moreover, as we have shown, phase information provides a unique
fingerprint of gravitational instability developed from Gaussian
initial conditions (which have maximal phase entropy). Methods
such as those described above can therefore be used to test this
standard paradigm for structure formation. They can also furnish
direct tests of the presence of initial non-Gaussianity
[Ferreira et al. 1998,
Pando et al. 1998,
Bromley & Tegmark 1999].
But there is also an important general point to be made about the philosophy of large-scale structure studies. The existing approaches are dominated by a direct methodology. A hypothetical mixture of ingredients is constructed (see Section 2.6), and ab initio simulations used to propagate the initial conditions to a model of reality that would pertain if the model were true. If it fails, one revises the model. But there are now many models which agree more-or-less with the existing data. These also contain free parameters that can be used to massage them into compliance with observations. In particular, we can appeal to a complex non-linear and non-local bias to achieve this. The usefulness of these direct hypothesis tests is therefore open to doubt.
The stumbling block lies with the fact that we still cannot reliably predict the relationship between galaxies and mass. Although theory seems to have slowed down, we do now have the prospect of huge amounts of data arriving on the scene. A better approach than the direct one I have mentioned is to treat those unknown aspects of galaxy formation as an inverse problem. Given a sufficiently flexible and realistic model we should infer parameter values from observations. To exploit this approach requires the development of simple models that can be used to close the inductive loop connecting theory with observations. For this reason it is important to continue constructing simple models of bias and galaxy clustering generally, since these are such valuable inferential tools.
As the raw material is increasing in both quality and quantity, it is time to refine our statistical technology so that the subtle and precious artifacts previously ignored can be both detected and extracted.