


The VELMOD analysis can tell us which velocity field models - which
values of
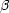 I,
I,
 v,
wLG, and quadrupole parameters - are "better"
than others. However, as with maximum likelihood approaches generally, by
itself it cannot tell us which, if any, of these models is an acceptable
fit to the data. This is because we do not have precise, a priori knowledge
of the two sources of variance, the velocity noise
v
and the TF scatter
TF.
Instead, we have treated these quantities as free parameters and determined
their values by maximizing likelihood. As a result, a standard
v,
wLG, and quadrupole parameters - are "better"
than others. However, as with maximum likelihood approaches generally, by
itself it cannot tell us which, if any, of these models is an acceptable
fit to the data. This is because we do not have precise, a priori knowledge
of the two sources of variance, the velocity noise
v
and the TF scatter
TF.
Instead, we have treated these quantities as free parameters and determined
their values by maximizing likelihood. As a result, a standard
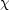 2
statistic will be ~ 1 per degree of freedom (dof), even if the fit is poor.
2
statistic will be ~ 1 per degree of freedom (dof), even if the fit is poor.
Of course, we can ask whether or not the values
of v
and TF
obtained from VELMOD agree with independent estimates. It is reassuring
that they do. We find
TF
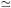 0.46
mag for both the A82 and
MAT
samples, within the range estimated by
Willick et al. (1996)
by methods independent of
peculiar velocity models. However, this agreement is of limited
significance. TF scatter is very sensitive to non-Gaussian
outliers (Section 4.1), and thus to
precisely which objects have been excluded. Furthermore, the
MAT
subsample used here is only about half as large as the
MAT
subsample used by
Willick et al. (1996)
to estimate its scatter. The VELMOD result for the velocity
noise, v
125 km
s-1, is remarkably small and appears consistent with recent
studies for the value of the velocity field outside of clusters based on
independent methods (e.g.,
Miller, Davis, & White
1996
and Strauss et al. 1997).
Indeed, because ~ 90 km
s-1 may be attributed to IRAS velocity prediction errors
(Section 3.2), our value
of v
suggests a true one-dimensional velocity noise of
0.46
mag for both the A82 and
MAT
samples, within the range estimated by
Willick et al. (1996)
by methods independent of
peculiar velocity models. However, this agreement is of limited
significance. TF scatter is very sensitive to non-Gaussian
outliers (Section 4.1), and thus to
precisely which objects have been excluded. Furthermore, the
MAT
subsample used here is only about half as large as the
MAT
subsample used by
Willick et al. (1996)
to estimate its scatter. The VELMOD result for the velocity
noise, v
125 km
s-1, is remarkably small and appears consistent with recent
studies for the value of the velocity field outside of clusters based on
independent methods (e.g.,
Miller, Davis, & White
1996
and Strauss et al. 1997).
Indeed, because ~ 90 km
s-1 may be attributed to IRAS velocity prediction errors
(Section 3.2), our value
of v
suggests a true one-dimensional velocity noise of
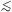 90
km s-1. Still, the small
v is
not necessarily diagnostic; for demonstrably poor models (e.g.,
I
90
km s-1. Still, the small
v is
not necessarily diagnostic; for demonstrably poor models (e.g.,
I
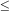 0.2), we
find an even smaller value of
v.
Thus, an alternative approach is required for identifying a poor fit.
0.2), we
find an even smaller value of
v.
Thus, an alternative approach is required for identifying a poor fit.
Let us consider fitting a straight line
y = ax + b by least squares to
data (xi, yi) whose
errors are unknown. One obtains a, b, and also the rms
scatter about the fit. Because the scatter is derived from the fit, the
2 statistic
is ~ 1 per dof by construction. However, if the straight line is a
bad fit - if, say, the relation between y and x is
actually quadratic - then
the residuals from the fit will exhibit coherence.
Coherent residuals in excess of what is expected from the observed scatter
would signify that a model is a poor fit. In this section, we will make
such an assessment for the VELMOD residuals. First, we will define a
suitable residual and plot it on the sky. We will demonstrate coherence
and incoherence of the residuals for "poor"
and "good"
models, respectively, by plotting residual autocorrelation functions.
Motivated by these considerations, we will define and compute a statistic
that measures goodness of fit.