


The information criteria have a deep underpinning in the theory of statistical inference, but fortunately have a very simple expression. The key aim is to make an objective comparison of different models (here interpretted as different selections of cosmological parameters to vary) which may feature different numbers of parameters. Usually in cosmology a basic selection of `essential' parameters is considered, to which additional parameters might be added to make a more general model. It is assumed that the models will be compared to a fixed dataset using a likelihood method.
Typically, the introduction of extra parameters will allow an improved fit to the dataset, regardless of whether or not those new parameters are actually relevant. 1 A simple comparison of the maximum likelihood of different models will therefore always favour the model with the most parameters. The information criteria compensate for this by penalizing models which have more parameters, offsetting any improvement in the maximum likelihood that the extra parameters might allow.
The simplest procedure to compare models is the likelihood ratio test
(Kendall & Stuart
1979,
ch. 24), which can be applied when the simple model is nested within a
more complex model. The quantity
2 ln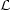 simple /
complex, where
is the maximum likelihood
of the model under consideration, is approximately chi-squared
distributed and
standard statistical tables can be used to look up the significance of any
increase in likelihood against the number of extra parameters introduced.
However the assumptions underlying the test are often violated in
astrophysical situations
(Protassov et al. 2002).
Further, one is commonly interested in comparing models which are not
nested.
simple /
complex, where
is the maximum likelihood
of the model under consideration, is approximately chi-squared
distributed and
standard statistical tables can be used to look up the significance of any
increase in likelihood against the number of extra parameters introduced.
However the assumptions underlying the test are often violated in
astrophysical situations
(Protassov et al. 2002).
Further, one is commonly interested in comparing models which are not
nested.
The Akaike information criterion (AIC) is defined as
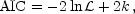 |
(1) |
where is the maximum
likelihood and k the number of parameters of the model
(Akaike 1974).
The best model is the model which minimizes the AIC, and there is no
requirement for the models to be nested. Typically, models with too few
parameters give a poor fit to the data and hence have a low
log-likelihood, while those with too many are penalized by the second
term. The form of the AIC comes from minimizing the Kullback-Leibler
information entropy, which measures the
difference between the true distribution and the model distribution. The
AIC arises from an approximate minimization of this entropy; an
explanation geared to astronomers can be found in
Takeuchi (2000),
while the full statistical justification can be found in
Sakamoto et al. (1986)
and Burnham & Anderson
(2002).
The Bayesian information criterion (BIC) was introduced by Schwarz (1978), and can be defined as
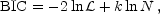 |
(2) |
where N is the number of datapoints used in the fit (in current cosmological applications, this will be of order one thousand). It comes from approximating the Bayes factor (Jeffreys 1961; Kass & Raftery 1995), which gives the posterior odds of one model against another presuming that the models are equally favoured prior to the data fitting. Although expressed in terms of the maximum likelihood, it is therefore related to the integrated likelihood.
It is unfortunate that there are different information criteria in the literature, which forces one to ask which is better. Extensive Monte Carlo testing has indicated that the AIC tends to favour models which have more parameters than the true model (see e.g. Harvey 1993; Kass & Raftery 1995). Formally, this was recognized in a proof that the AIC is `dimensionally inconsistent' (Kashyap 1980), meaning that even as the size of the dataset tends to infinity, the probability of the AIC incorrectly picking an overparametrized model does not tend to zero. By contrast, the BIC is dimensionally consistent, as the second term in its definition ever more harshly penalizes overparametrized models as the dataset increases in size, and hence the BIC does always pick the correct model for large datasets. Burnham & Anderson (2002) generally favour the AIC, but note that the BIC is well justified whenever the complexity of the true model does not increase with the size of the dataset and provided that the true model can be expected to be amongst the models considered, which one can hope is the case in cosmology. Accordingly, it seems that that BIC should ordinarily be preferred. Note though that for any likely dataset ln N > 2, and hence the AIC is always more generous towards extra parameters than the BIC. Hence the AIC remains useful as it gives an upper limit to the number of parameters which should be included.
In either case, the absolute value of the criterion is not of interest, only the relative value between different models. A difference of 2 for the BIC is regarded as positive evidence, and of 6 or more as strong evidence, against the model with the larger value (Jeffreys 1961; Mukherjee et al. 1998).
The rather limited literature on cosmological model selection has thus far not used the information criteria, but has instead used the more sophisticated idea of Bayesian evidence (see e.g. Jaynes 2003), which compares the total posterior likelihoods of the models. This requires an integral of the likelihood over the whole model parameter space, which may be lengthy to calculate, but avoids the approximations used in the information criteria and also permits the use of prior information if required. It has been used in a variety of cosmological contexts by Jaffe (1996), Drell, Loredo & Wasserman (2000), John & Narlikar (2002), Hobson, Bridle & Lahav (2002), Slosar et al. (2003), Saini, Weller & Bridle (2003), and Niarchou, Jaffe & Pogosian (2003).
1 In cosmology, a new parameter will usually be a quantity set to zero in the simpler base model, and as the likelihood is a continuous function of the parameters, it will increase as the parameter varies in either the positive or negative direction. However some parameters are restricted to positive values (e.g. the amplitude of tensor perturbations), and in that case it may be that the new parameter does not improve the maximum likelihood. Back.