Copyright © 1988 by Annual Reviews. All rights reserved
| Annu. Rev. Astron. Astrophys. 1988. 26:
245-294 Copyright © 1988 by Annual Reviews. All rights reserved |



3.1.2. STATISTICAL PROBABILITY TECHNIQUES
To study voids by means of statistical probabilities, a statistic must first be identified that provides a well-defined signature for the presence of voids. Then the probability-density or distribution function of that parameter is calculated from the locational coordinates of the galaxies in the sample. Finally, a comparison is made between this observed probability function and the predicted probability functions calculated from mathematical and astrophysical models with the same number of galaxies and the same observational selection functions as in the observational sample to identify that model which provides the best fit to the observed probability function.
Early statistical studies of large-scale structure applied primarily
the spatial two-point and occasionally n-point correlation functions
(cf. 142,
142a,
pp. 138-256; 198). Correlation functions are
insensitive to void structure (cf.
77,
84,
114a), so the extensive
work on determining correlation functions from observational data,
while contributing to our general knowledge of large-scale structure,
contributed not at all to the discovery of voids. One can think of the
observed two-point correlation function, the structure indicator
SI of
Rij, as a construction from the totality of the
N(N - 1) / 2 separation
vectors of length Rij (where the N galaxies in
the homogeneous sample
are numbered from i, j = 1 to N). The two-point
correlation function
provides information on the observed large-scale structure relative to
a (structureless) model with Poisson-distributed locational
coordinates, and it is defined as
SI = [N(Rij) /
N(Rij)Poisson] - 1,
where N(Rij) is the number of observed galaxy
pairs with Rij to
Rij +
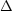 Rij.
Here
Rij
is a standard interval chosen to be sufficiently large
so that SI is statistically well determined at the smallest
Rij of
interest, but small compared with the effective radius of the cosmic
volume containing the sample of N galaxies.
N(Rij)Poisson
is the corresponding number of pairs with Rij to
Rij +
Rij
averaged over NS samples (where NS
Rij.
Here
Rij
is a standard interval chosen to be sufficiently large
so that SI is statistically well determined at the smallest
Rij of
interest, but small compared with the effective radius of the cosmic
volume containing the sample of N galaxies.
N(Rij)Poisson
is the corresponding number of pairs with Rij to
Rij +
Rij
averaged over NS samples (where NS
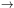
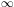 ), each sample with N
galaxies constructed from an
initially Poisson distribution of locational coordinates to which the
observationally derived selection functions have been applied. The
n-point correlation function is obtained by generalizing these
concepts to encompass the joint distribution of the n separations:
Rij, Rik, etc. The observed
two-point correlation function is
observationally well described by a power law, i.e.
SI = ARijx, where A
is the correlation amplitude and x is the "slope." The correlation
scale length RL is the value of Rij
for which SI = 1, i.e.
RL = A-1/x. Analysis of data on
locational coordinates of galaxies and galaxy clusters indicates that
x
), each sample with N
galaxies constructed from an
initially Poisson distribution of locational coordinates to which the
observationally derived selection functions have been applied. The
n-point correlation function is obtained by generalizing these
concepts to encompass the joint distribution of the n separations:
Rij, Rik, etc. The observed
two-point correlation function is
observationally well described by a power law, i.e.
SI = ARijx, where A
is the correlation amplitude and x is the "slope." The correlation
scale length RL is the value of Rij
for which SI = 1, i.e.
RL = A-1/x. Analysis of data on
locational coordinates of galaxies and galaxy clusters indicates that
x 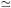 - 1.8 for both
types of cosmic object, but
RL 10
Mpc for galaxies and RL
50 Mpc for galaxy
clusters (cf. Section 2.2.1). Additional
information on large-scale
structure is contained within the values of corresponding parameters
for the hierarchy of n-point correlation functions; for example,
within this framework, Fry
(78a)
studied statistics to quantify the
visual impression of filaments in galaxy maps.
- 1.8 for both
types of cosmic object, but
RL 10
Mpc for galaxies and RL
50 Mpc for galaxy
clusters (cf. Section 2.2.1). Additional
information on large-scale
structure is contained within the values of corresponding parameters
for the hierarchy of n-point correlation functions; for example,
within this framework, Fry
(78a)
studied statistics to quantify the
visual impression of filaments in galaxy maps.
White (211c)
derived and displayed relations that can be used to
express any quantitative measures of clustering in terms of the
hierarchy of correlation functions. He found that on scales less than
the expected nearest neighbor distance most measures are influenced
only by the lowest order correlation functions, and on all larger
scales the measures depend significantly on higher order correlations
only. White then suggested a particularly appealing statistical
probability function that is influenced by correlation of all orders:
the probability density function p(r), or, alternatively, the
distribution function, g(r) =
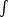 r
p(r)dr, of the distance r from a
randomly chosen point to its nearest galaxy neighbor; p(r)
and g(r) are very sensitive to the presence of voids (cf.
3). For a Poisson
reference model of galaxies with randomly distributed locational
coordinates [i.e. the local number densities
n(x, y, z) equal the
global number density n to within Poisson uncertainties], we have
g(r) = e-nr. The probability functions
p(r) and g(r), and other closely
related probability functions, seem to encompass the entire set of
probability density and distribution functions that have been used to
study the nature of voids as indicated by the locational properties of
homogeneous samples of galaxies. Void-sensitive probability functions
of this type have been derived for many mathematical and astrophysical
models (cf.
3,
78,
84,
171);
as demonstrated by Fry
(78), for example,
the main advantage of this type of analysis is that evolution and
other effects are reduced to a single statistic whose distribution is
model sensitive. Some of these mathematical and astrophysical models
have been subjected to the selection functions derived from
observational data of homogeneous samples of cosmic objects, and the
resulting predicted probability functions have been compared with the
corresponding empirical probability function derived directly from the
observational data (cf.
31,
140,
167,
186,
208,
209). Probability
functions derived from observational samples of galaxies with
different ranges of absolute luminosity are consistent with the
assumption that the less luminous galaxies do not fill in the voids
(167,
186;
see also Section 2.1.2). Finally, I note
that the above
statistical procedures to study voids, which have been applied
extensively to samples of galaxies, seem not to have been applied to
samples of Abell clusters of galaxies. This may be a consequence of a
reluctance to accept the homogeneity of the statistical sample of
Abell clusters (which was identified visually). Abell
(4) documents
the care taken to insure that the sample is statistically homogeneous
so that it can be used for statistical studies [with the proviso that
care must be exercised to allow for effects of the random and
systematic uncertainties of the data, as has been done in the work by,
e.g., N. Bahcall et al. (Section 2.2.1)].
Concrete studies to settle this issue are in progress.
r
p(r)dr, of the distance r from a
randomly chosen point to its nearest galaxy neighbor; p(r)
and g(r) are very sensitive to the presence of voids (cf.
3). For a Poisson
reference model of galaxies with randomly distributed locational
coordinates [i.e. the local number densities
n(x, y, z) equal the
global number density n to within Poisson uncertainties], we have
g(r) = e-nr. The probability functions
p(r) and g(r), and other closely
related probability functions, seem to encompass the entire set of
probability density and distribution functions that have been used to
study the nature of voids as indicated by the locational properties of
homogeneous samples of galaxies. Void-sensitive probability functions
of this type have been derived for many mathematical and astrophysical
models (cf.
3,
78,
84,
171);
as demonstrated by Fry
(78), for example,
the main advantage of this type of analysis is that evolution and
other effects are reduced to a single statistic whose distribution is
model sensitive. Some of these mathematical and astrophysical models
have been subjected to the selection functions derived from
observational data of homogeneous samples of cosmic objects, and the
resulting predicted probability functions have been compared with the
corresponding empirical probability function derived directly from the
observational data (cf.
31,
140,
167,
186,
208,
209). Probability
functions derived from observational samples of galaxies with
different ranges of absolute luminosity are consistent with the
assumption that the less luminous galaxies do not fill in the voids
(167,
186;
see also Section 2.1.2). Finally, I note
that the above
statistical procedures to study voids, which have been applied
extensively to samples of galaxies, seem not to have been applied to
samples of Abell clusters of galaxies. This may be a consequence of a
reluctance to accept the homogeneity of the statistical sample of
Abell clusters (which was identified visually). Abell
(4) documents
the care taken to insure that the sample is statistically homogeneous
so that it can be used for statistical studies [with the proviso that
care must be exercised to allow for effects of the random and
systematic uncertainties of the data, as has been done in the work by,
e.g., N. Bahcall et al. (Section 2.2.1)].
Concrete studies to settle this issue are in progress.
Void-sensitive probability functions such as p(r) and g(r) derived from observational galaxy data have been related to the amplitudes of the n-point correlation functions by Sharp (179) [from data in the Zwicky catalogue (220)] and by Bouchet & Lachieze-Rey (31) [from data in the CfA catalog (93a)]. Masson (114a) points out that correlation function analysis cannot distinguish between overdensity and underdensity structure. Fry (77) and Hamilton (84) show that the qualitative and to some degree quantitative aspects of n(x, y, z) << n, the spatial density function at the small local densities appropriate to voids that is recovered from the amplitudes of the n-point correlation functions, is largely independent of the exact sequence of amplitudes [i.e. the correlation amplitudes provide a poor characterization of n(x, y, z) within voids].