


2.7. Blind surveys and number counts
SZ-effect selected samples of clusters of galaxies would be ideal for many cosmological purposes, not only for the measurement of the distance scale. This is because the SZ effects are redshift independent in surface brightness terms, so that clusters can be detected to high redshift. An SZ effect survey could therefore be constructed to be almost mass limited (as shown by the flat efficiency curve in Fig. 2), as well as being orientation independent.
A sample of clusters found by such a survey should therefore provide a
fairly direct indicator of
how many clusters of a given mass have assembled at any redshift, and
the cluster count and redshift distribution can be used to set strong
constraints on
 8 and
8 and
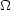 m 0 (e.g.,
Fan and Chiueh 2001)
provided that our understanding of the early phases of cluster
formation is accurate. Alternatively, we could regard the cluster
statistics as a test of our models of cluster formation.
m 0 (e.g.,
Fan and Chiueh 2001)
provided that our understanding of the early phases of cluster
formation is accurate. Alternatively, we could regard the cluster
statistics as a test of our models of cluster formation.
Large surveys for clusters in their SZ effects are only now beginning to be made: up until the present, the sensitivity of interferometers, radiometer arrays, and bolometer arrays has been insufficient to allow surveys of a sufficiently large area of sky for useful statistics on the cluster population to be developed. Perhaps the fastest approaches involve the use of radiometer and bolometer arrays, and the best areas to survey are those which already have significant optical and X-ray coverage (since confirmation of potential cluster detections is a crucial aspect of the work).
Clearly, the absolute calibration of the SZ effects is not a critical issue if the aim of blind surveys is merely to detect clusters, but the surveys will have to contend with the problems of radio source and MBR confusion (Sec. 2.3.2). Interpreting the results of the survey must rely on a good knowledge of the selection function: the efficiency of cluster detection as a function of redshift in the presence of MBR fluctuations, radio sources (with a population which evolves with redshift), etc.. The calculation of this selection function will depend on the accuracy of the cluster model (Sec. 2.2.2).