


4.1 Methodology
In searching for correlations as we were in Section 2, we were hypothesis testing; in model fitting (Section 3) we were involved in parameter estimation. The entire science of Statistical inference might be considered as parameter estimation followed by hypothesis testing; and the frequentists might be happy with this. The Bayesians are most assuredly not happy; and indeed if experiments were properly designed to test hypotheses, Bayesians would be right - the two-stage process should be unnecessary at best.
However, life is not like this. We are given parameters, and we need to compare and decide something. What we really are involved in is decision theory and risk analysis. Given our data, and/or somebody else's, we need to do the following:
Set up two possible and exclusive hypotheses, each with an associated terminal action:
H0 the null hypothesis or hypothesis of no effect, usually formulated to be rejected, and
H1, the alternative, or research hypothesis.
Specify a priori the significance level
 ; choose a test which (a)
approximates the conditions and (b) finds what is needed; obtain the
sampling distribution and the region of rejection, whose area is a
fraction of the total area in
the sampling distribution.
; choose a test which (a)
approximates the conditions and (b) finds what is needed; obtain the
sampling distribution and the region of rejection, whose area is a
fraction of the total area in
the sampling distribution.
Run the test; reject H0 if the
test yields a value of the
statistic whose probability of occurrence under H0 is
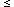 .
.
Carry out the terminal action.
It is vital to emphasize point (2). The significance level has to be chosen before the value of the test statistic is glimpsed; otherwise some arbitrary convolution of the data plus the psychology of the investigator is being tested.
There are two types of error involved in the process, traditionally referred to (surprisingly enough) as types I and II.
Type I error occurs when H0 is in fact true, and the
probability of
a type I error is the probability of rejecting H0 when
it is in fact true, i.e. .
The type II error occurs when H0 is false, and the
probability of a
type II error is the probability 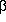 of the failure to reject a false
H0; is not related to in any direct or obvious way. The power of a
test is the probability of rejecting a false H0, or 1
- .
of the failure to reject a false
H0; is not related to in any direct or obvious way. The power of a
test is the probability of rejecting a false H0, or 1
- .
The sampling distribution is the probability distribution of the
test statistic, i.e. the frequency distribution of area unity
including all values of the test statistic under
H0. The probability
of the occurrence of any value of the test statistic in the region of
rejection is less than , by
definition; but where the region of
rejection lies within the sampling distribution is dependent on
H1. If
H1 indicates direction, then there is a single region
of rejection and
the test is one-tailed: if no direction is indicated, the region of
rejection is comprised of the two ends of the distribution and we are
dealing with a two-tailed test.
Let us be clear that both parametric and non-parametric tests follow this procedure; both need to produce a test statistic and a sampling distribution for this statistic. The non-parametric aspect arises in that the test statistic does not itself depend upon properties of the population(s) from which the data were drawn.
It is worth emphasizing again why we are going to concentrate on the non-parametric tests.
These make fewer assumptions about the data. If indeed the underlying distribution is unknown, there is no alternative.
If the sample size is small, probably we must use a non-parametric test.
The non-parametric tests can cope with data in non-numerical form, e.g. ranks or classifications. There may be no parametric equivalent.
Non-parametric tests can treat samples of observations from several different populations.
What are the counterarguments?
Binning is bad. And the power of non-parametric tests may be somewhat less, but normally no more than 10 per cent. Taken together, the two items may, in some particular cases, represent a severe loss of efficiency.
The Bayesian equivalents of non-parametric tests do not yet exist (Gull & Fielden 1986).