


2. STATISTICS AND ASTRONOMICAL SURVEYS
Large astronomical surveys from new, high-throughput detectors and
observatories are powerful motivators for more effective statistical
techniques. Observatories now frequently generate gigabytes of
information every day, with terabyte size raw databases which produce
reduced catalogues of 106-109 objects. These
catalogues, which
may include up to dozens of observational properties of each object,
often contain heterogeneous populations which must be isolated prior
to detailed analysis. Althoug there are many types of astronomical
surveys with many different goals, the statistical problems arising in
their analysis can often be divided into three stages. We treat the
first two stages very briefly here to concentrate on the final phase.
Reducing raw data into images The treatment of the raw data
from the telescope or satellite
observatory can be very complex, and has embedded within it many
choices of statistical methods. These methods are typically described
in internal technical memoranda which are rarely published or
publically examined, and sometimes are invisible except for comments
in source code. The IRAS Faint Source Survey Explanatory Supplement
(Moshir et al.
1992) offers a glimpse into this complex nether-world:
a median filter is applied to reduce noise; outliers are detected to
remove particle events; overlapping scans are combined and
interpolated; fluxes are estimated with a trimmed mean; signal is
extracted with a S / N 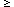 3.5 criterion; distinct sources are devined by
a complicated source-merging procedure; sky positions are derived from
recursive Kalman filtering and connected polynomial segment fitting to
satellite gyroscope time series data. The IRAS analysis benefits from
robust statistical procedures such as the median and trimmed mean
rather than the usual mean, which have been developed by statisticians
over the past 20 years (e.g.,
Hoaglin et al.
1983). The problems addressed here are specific to each instrument
and survey, and general advice has limited value.
3.5 criterion; distinct sources are devined by
a complicated source-merging procedure; sky positions are derived from
recursive Kalman filtering and connected polynomial segment fitting to
satellite gyroscope time series data. The IRAS analysis benefits from
robust statistical procedures such as the median and trimmed mean
rather than the usual mean, which have been developed by statisticians
over the past 20 years (e.g.,
Hoaglin et al.
1983). The problems addressed here are specific to each instrument
and survey, and general advice has limited value.
Reducing images to catalogues The analysis of astronomical
images can be very complicated. In
sparsely occupied images from photon-counting detectors (as in X-ray
and gamma-ray astronomy), efforts concentrate on detecting sources
above an uninteresting background. Methods include maximum likelihood
analysis based on the Poisson distribution, matched filtering and
Voronoi tesselations. In fully occupied grey-scale images, a wide
variety of image restoration methods have been applied to deconvolve
point spread functions and reduce noise: least squares fitting;
Lucy-Richardson method; maximum entropy and other Bayesian methods,
neural networks, Fourier and wavelet filtering (e.g.,
Narayan & Nityananda 1986;
Perley et al. 1989;
Hanisch & White 1993;
Starck & Murtagh 1994;
Lahav et al.
1995).
Many of these methods rest upon developments in statistical methodology.
Much work has also been directed to the automated analysis and
classification of objects on images, particularly the discrimination
of stars from galaxies on optical band photographic plates and CCD
images. Each object is characterized by a number of properties (e.g.,
moments of its spatial distribution, surface brightness, total
brightness, concentration, asymmetry), which are then passed through a
supervised classification procedure. Methods include multivariate
clustering, Bayesian decision theory, neural networks, k-means
partitioning, CART (Classification and Regression Trees) and oblique
decision trees, mathematical morphology and related multiresolution
methods (Bijaoui et
al. 1997;
White 1997). Such
procedures are crucial to the creation of the largest astronomical
databases with 1-2 billion objects derived from digitization of
all-sky photographic surveys.
The scientific product of multi-wavelength surveys is frequently a
large table with rows representing individual stars, galaxies,
sources or locations and columns representing observed or inferred
properties. Often a single survey effort will produce multiwavelength
results, as in the four infrared of IRAS, the five photometric colors
of the Sloan Digital Sky Survey, or spectral bands in the ROSAT
All-Sky Survey. Analysis of such data is the domain of multivariate
analysis. We therefore concentrate on multivariate statistical
methodology in the following sections.