


3. FUNDAMENTALS OF MULTIVARIATE ANALYSIS AND
CLUSTERING
A multivariate analysis often begins with the computation of simple
statistics of the sample: the mean and standard deviation of each
variable; linear (Pearson's r) or rank (Spearman's 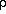 , or Kendall's
, or Kendall's
 ) correlation coefficients
between pairs of variables.
Statisticians often divide each value by the sample standard deviation
for that variable (known as `standardizing' or `Studentizing' the
sample), while astronomers often take a log transform or consider the
ratio of two variables with the same units.
) correlation coefficients
between pairs of variables.
Statisticians often divide each value by the sample standard deviation
for that variable (known as `standardizing' or `Studentizing' the
sample), while astronomers often take a log transform or consider the
ratio of two variables with the same units.
Study of pair-wise relationships between variables provides a
valuable but fundamentally limited view of the data. A multivariate
database should be viewed as a cloud of points (or vectors) in p-space
which can have any form of structure, not just planar correlations
parallel to the axes. The sample covariance matrix S contains
information for this more general approach, and lies at the root of
many methods of multivariate analysis developed during the
1930-60s. The method most widely used in astronomy is principal
components analysis. Here the 1st principal component is
e1T X where
ek is the eigenvector of S corresponding to the
kth largest value. This is equivalent to finding by the direction in
p-space where the
data are most elongated using least-squares to minimize the variance.
The second component finds the elongation direction after the first
component is removed, and so forth. Important applications in
astronomy include the stellar spectral classification
(Deeming 1964),
eludication of Hubble's tuning-fork spiral galaxy classification
system (Whitmore
1984), and characterization of relationships between
emission lines, broad absorption lines and the continuum in quasar
spectra (Francis et
al. 1992).
In canonical analysis, the variables are divided into two preselected
groups and the eigenvectors of the cross-sample covariance matrix
S11-1/2 S12
S22-1 S21
S11-1/2 gives the principal linear
relationships between the two sets of variables. This might be used to relate
stellar metallicity variables with kinematic variables to study
Galactochemical evolution, or stellar magnetic activity indicators
with bulk star properties to study dynamo theory.
A sample, collected from one or more multiwavelength surveys, often
will not constitute a single type of astronomical
object. Variance-covariance structure residing within the matrix S may
thus reflect heterogeneity of the sample, rather than astrophysical
processes within a homogeneous class. It is thus important to search
for groupings in p-space using multivariate algorithms. Dozens of
such methods have been proposed. Unfortunately, most are procedural
algorithms without formal statistics (i.e., no probabilistic measures
of merit) and there is little mathematical guidance which produces
`better' clusters.
Hierarchical clustering procedures produces small clusters within
larger clusters. One such procedure, `percolation' or the
`friends-of-friends' algorithm is a favorite among astronomers. It is
called single linkage clustering obtained by successively removing the
longest branches of the unique minimal spanning tree connecting
the n points in p-space. Single linkage produces long
stringy clusters. This
may be appropriate for galaxy clustering studies, but researchers in
other fields usually prefer average or complete linkage algorithms
which produce more compact clusters. The many varieties of
hierarchical clustering arise because the scientist must chose the
metric (e.g., should the `distance' between objects be Euclidean or
squared?), weighting (e.g., how is the average location of a cluster
defined?), and criteria for merging clusters (e.g., should the total
variance or internal group variance be minimized?).
An alternative method with a more rigorous mathematical foundation is
k-means partitioning. It finds the combination of k groups that
minimizes intragroup variance. However, it is necessary to specify k
in advance.