


2.2. VELMOD
The approach we take in this paper, "VELMOD," is a maximum likelihood method designed to surmount several of the difficulties that face POTIRAS and ITF. VELMOD generalizes and improves upon the Method II approach to velocity analysis. Method II takes as its basic input the TF observables (apparent magnitude and velocity width) and redshift of a galaxy, and asks the following: what is the probability of observing the former, given the value of the latter? It then maximizes this probability over the entire data set with respect to parameters describing the TF relation and the velocity field. The underlying assumption of Method II is that a galaxy's redshift, in combination with the correct model of the velocity field, yields its true distance, which then allows the probability of the TF observables to be computed. This analytic approach was developed originally by Schechter (1980) and was used later by Aaronson et al. (1982b), Faber & Burstein (1988), Strauss (1989), Han & Mould (1990), Hudson (1994), Roth (1994), and Schlegel (1995), among others.
The main problem with Method II is its
assumption that a unique redshift-distance mapping is possible. This
assumption breaks down for two reasons. First, it is only approximately
true that the redshift of a galaxy is equal to the sum of its distance and
its predicted peculiar velocity (cf. eq. [A1]); there is true velocity
noise generated on very small
(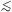 1 Mpc)
scales, as well as inaccuracy of the velocity model (even for the correct
1 Mpc)
scales, as well as inaccuracy of the velocity model (even for the correct
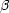 ) due
to nonlinear effects and shot noise in the density field. Second, even in
the absence of noise, the redshift-distance relation, in principle, can be
multivalued: more than one distance along the line of sight can correspond
to a given redshift. VELMOD accounts for all of these effects statistically
by replacing the unique distance of Method II with the joint
probability distribution of redshift and distance. This distribution is
constructed to allow for both noise and multivaluedness. The distance
dependence is then integrated out
(Section 2.2.1),
yielding the correct probability distribution of the TF observables
given redshift.
) due
to nonlinear effects and shot noise in the density field. Second, even in
the absence of noise, the redshift-distance relation, in principle, can be
multivalued: more than one distance along the line of sight can correspond
to a given redshift. VELMOD accounts for all of these effects statistically
by replacing the unique distance of Method II with the joint
probability distribution of redshift and distance. This distribution is
constructed to allow for both noise and multivaluedness. The distance
dependence is then integrated out
(Section 2.2.1),
yielding the correct probability distribution of the TF observables
given redshift.
There are two additional advantages to the
VELMOD approach. First, it requires neither a priori calibration of the TF
relations (as does POTENT) nor matching of the input data from disparate
samples (as does ITF). An individual TF calibration for each independent
sample occurs naturally as part of the analysis. Second, it does not
require smoothing of the input TF data, and thus allows as high-resolution
an analysis as the data intrinsically permit. This second feature, along
with its allowance for velocity noise and triple-valued zones, makes VELMOD
well suited for probing the local (cz
3000
km s-1) velocity field. An analysis of local data is desirable
because random and systematic errors in both the IRAS and TF data
are less important nearby than far away.