


5.2.1. Using Residual Correlations to Identify Poor Fits Quantitatively
In order to compare the observed residual
correlations with the results from the mock catalogs, we would like to
define a single statistic that summarizes the deviation of
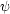 (
( )
from unity. Let us define
)
from unity. Let us define
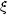 ()
()
 Np()
()
(cf. eq. [25]). In Appendix C, we show that
()
approximates a Gaussian random variable of mean zero and
variance Np(),
if indeed the VELMOD residuals are uncorrelated on scale
. [This
property was used to compute the error bars on
()
above.] To the degree this approximation is a good one, the quantity
Np()
()
(cf. eq. [25]). In Appendix C, we show that
()
approximates a Gaussian random variable of mean zero and
variance Np(),
if indeed the VELMOD residuals are uncorrelated on scale
. [This
property was used to compute the error bars on
()
above.] To the degree this approximation is a good one, the quantity
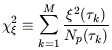
| (26) |
will be distributed approximately as a
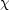 2
variable with M degrees of freedom, where M is the number
of separate bins in which
()
is calculated. In contrast, if the residuals are strongly correlated on any
scale ,
2
will exceed its expected value significantly.
2
variable with M degrees of freedom, where M is the number
of separate bins in which
()
is calculated. In contrast, if the residuals are strongly correlated on any
scale ,
2
will exceed its expected value significantly.
However, because a single galaxy
will appear in many different pairs in the correlation statistic, both
within and between bins in
, the
assumptions made above do not hold rigorously. In
Appendix C, we explore this issue
further. For now, we appeal to the mock
catalogs to assess how closely the quantity
2
follows 2
statistics. We computed it for each of the 20 mock catalog runs
(Section 3)
with 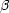 I
= 1. We carried out the calculation to a maximum separation of 6400 km
s-1, in bins of width 200 km s-1, so that M =
32, and found a
mean value <2> = 27.83±1.82, which
may be compared with an expected value of 32 for a
true 2
statistic. The rms scatter
in 2
was 8.15, which is the same as that expected for a true
2.
The difference between the mean and expected values is 2.3
I
= 1. We carried out the calculation to a maximum separation of 6400 km
s-1, in bins of width 200 km s-1, so that M =
32, and found a
mean value <2> = 27.83±1.82, which
may be compared with an expected value of 32 for a
true 2
statistic. The rms scatter
in 2
was 8.15, which is the same as that expected for a true
2.
The difference between the mean and expected values is 2.3
 , indicating
that 2
is not exactly a 2
statistic, for reasons discussed in Appendix C.
However, because the departure from true
2 statistics is
small, 2
is a useful statistic for measuring goodness of fit when calibrated against
the mock catalogs.
, indicating
that 2
is not exactly a 2
statistic, for reasons discussed in Appendix C.
However, because the departure from true
2 statistics is
small, 2
is a useful statistic for measuring goodness of fit when calibrated against
the mock catalogs.
Before presenting
2
for the real data, we consider its variation with
I
for the mock catalogs. In Figure 18,
we plot the average value
of 2
over the 20 mock catalogs at each value of
I
for which VELMOD was run. Although the minimum is
at I
= 1, it is not nearly as sharp as is that of the likelihood as function of
I
(e.g., Fig. 2); this statistic
does not have the power that the likelihood does for measuring
I.
Indeed, for a single realization (the open symbols),
the statistic has several local minima. However, it is apparent that
a 2
value much greater than its expected true value of ~ 28 will
indicate a poor fit of the model to the data.
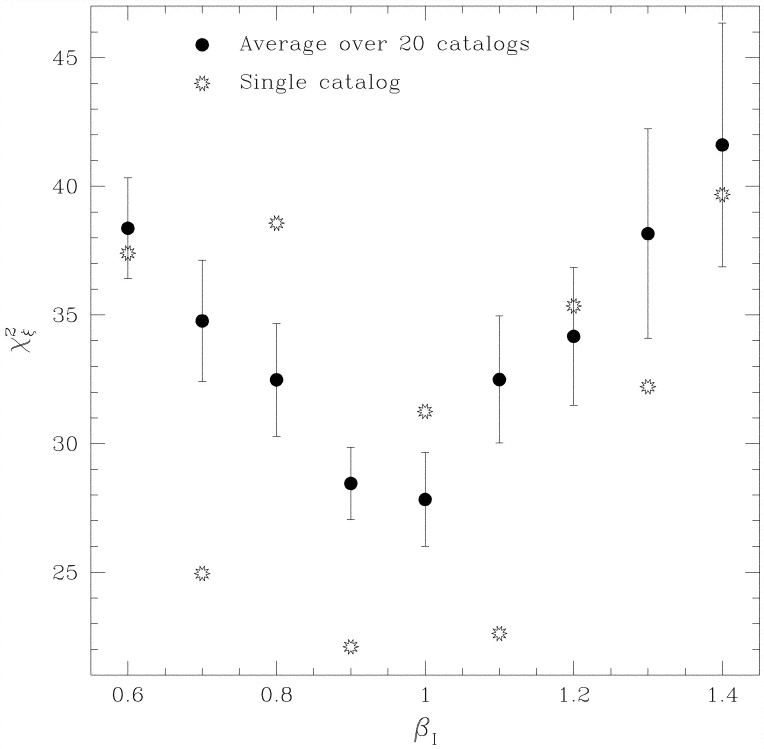
|
Figure 18. Residual correlation statistic
|
In Figure 19, we plot the
statistic 2 as a function
of I
for the real data, with and without the quadrupole included. The horizontal
lines indicate the expected value
of 2,
and the 1 and 3
deviations from it. Note first that the no-quadrupole
model does not provide an acceptable fit for any value of
I.
This is not a conclusion we could have reached on the basis of
the likelihood analysis alone. When the quadrupole is included, the only
values of
I
that are unambiguously ruled out
are I
= 0.1, 0.2, and 1.0. The best-fit model according to VELMOD,
I
= 0.5 plus quadrupole, also has the smallest value
of 2.
Given the multiple minima seen for one mock realization
in Figure 18, this is not necessarily deeply
significant. The
statistic 2
is suitable for identifying models that do not fit the data, but it
does not have the power of the likelihood statistic for discriminating
among those models that do fit.
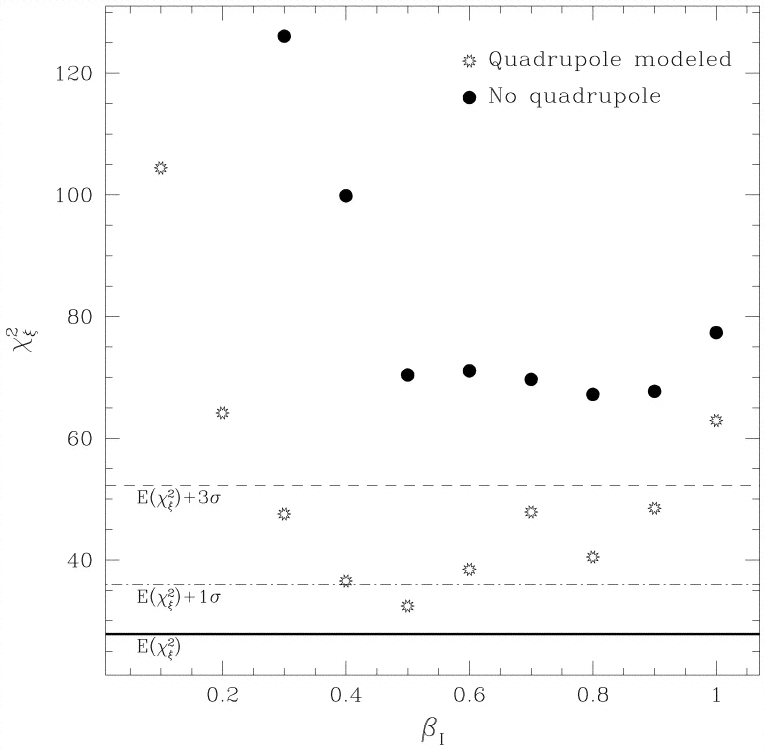
|
Figure 19. Residual autocorrelation
statistic |
In summary, the VELMOD likelihood
maximization procedure is the proper one for determining which value
of I
is better than others, but it cannot identify poor fits to our model. The
residual correlation
statistic 2
can identify unacceptable fits but does not have the power to determine
which of the acceptable fits is best. We have found that the IRAS
velocity field with
I
= 0.5, plus the external quadrupole, is both the best fit of those
considered and an acceptable fit. Values of
I
> 0.9
and I
< 0.3 are strongly ruled out.