Copyright © 1997 by Annual Reviews. All rights reserved
| Annu. Rev. Astron. Astrophys. 1997. 35:
101-136 Copyright © 1997 by Annual Reviews. All rights reserved |



The solution, Equation 1, proposed
by Kapteyn for his Problem I, gives the distance to a cluster or to any
subsample
of galaxies known, e.g. from the Hubble law or other velocity field model,
to be at the same distance. However, this presupposes that (a)
there is a sharp magnitude limit, with data complete up to
mlim, (b) the standard candle has a gaussian
distribution G(Mp,
 ), (c) the mean
Mp is known from local considerations (calibration), and
(d) the dispersion
is known. These are rather strict conditions. Fortunately, there are
situations
and aims that do not necessarily require a complete knowledge of all these
factors. For instance, study of the linearity of the Hubble law does not
need an absolute calibration of the standard candle, and knowledge of
is not necessary in all
methods for deriving the Hubble constant.
), (c) the mean
Mp is known from local considerations (calibration), and
(d) the dispersion
is known. These are rather strict conditions. Fortunately, there are
situations
and aims that do not necessarily require a complete knowledge of all these
factors. For instance, study of the linearity of the Hubble law does not
need an absolute calibration of the standard candle, and knowledge of
is not necessary in all
methods for deriving the Hubble constant.
4.1. The Bias-Free Redshift Range
Sandage & Tammann (1975a) introduced the concept of the bias-free distance (redshift) range in their Hubble parameter H-vs-log Vo diagram for luminosity classified spiral galaxies, which showed an increase of H with redshift. They explained this increase as caused by the truncation effect of the limiting magnitude, which makes the derived distances too small.
One expects an unbiased region at small true distances
(redshifts) because the sample can be distance-limited rather than
flux-limited,
hence no part of the faint end of the luminosity function is truncated at
appropriately small distances. It is only here that the Hubble constant can
be derived without correction for bias. Such a region of about constant H
was clearly visible in the H-vs-log Vo diagram of
Sandage & Tammann
(1975).
As a first approximation, they cut away galaxies more distant than a
fixed Vo (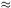 2000
km/s), independently of the morphological luminosity class. Actually, each
luminosity class has its own limiting distance, as Sandage & Tammann
recognized. Using one fixed Vo, one (a) loses
high-Vo data, part of it possibly unbiased, and (b)
allows a remaining bias due to intrinsically faint luminosity classes
with their proper limit <V>o. This was inspected by
Teerikorpi (1976),
where from the ST data (and their luminosity class calibration) the low
value of Ho = 41 was derived, in comparison with
Ho = 57 by
Sandage & Tammann
(1975).
I give this reference because it was a step toward the method of normalized
distances, later applied to samples of galaxies with TF measurements. The
similarity with Ho
43 by
Sandage (1993)
is probably not just a coincidence; both determinations relied on M101. An
up-to-date discussion of the bias in the luminosity class method was given
by Sandage (1996a).
2000
km/s), independently of the morphological luminosity class. Actually, each
luminosity class has its own limiting distance, as Sandage & Tammann
recognized. Using one fixed Vo, one (a) loses
high-Vo data, part of it possibly unbiased, and (b)
allows a remaining bias due to intrinsically faint luminosity classes
with their proper limit <V>o. This was inspected by
Teerikorpi (1976),
where from the ST data (and their luminosity class calibration) the low
value of Ho = 41 was derived, in comparison with
Ho = 57 by
Sandage & Tammann
(1975).
I give this reference because it was a step toward the method of normalized
distances, later applied to samples of galaxies with TF measurements. The
similarity with Ho
43 by
Sandage (1993)
is probably not just a coincidence; both determinations relied on M101. An
up-to-date discussion of the bias in the luminosity class method was given
by Sandage (1996a).