Copyright © 1994 by Annual Reviews. All rights reserved
| Annu. Rev. Astron. Astrophys. 1994. 32:
371-418 Copyright © 1994 by Annual Reviews. All rights reserved |



Given radial peculiar velocities ui sparsely sampled
at positions xi over a large volume, with
random errors  i, the first
goal is to extract the underlying three-dimensional velocity field,
v(x). Under GI, this velocity field is subject to certain
constraints, e.g. being associated with a mass-density
fluctuation field,
i, the first
goal is to extract the underlying three-dimensional velocity field,
v(x). Under GI, this velocity field is subject to certain
constraints, e.g. being associated with a mass-density
fluctuation field, 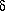 (x) - the other target for recovery. A field
can be defined by a parametric model or by the field values at
grid points. The number of independent parameters or
grid points should be much smaller than the number of data points
in view of the noisy data.
(x) - the other target for recovery. A field
can be defined by a parametric model or by the field values at
grid points. The number of independent parameters or
grid points should be much smaller than the number of data points
in view of the noisy data.
Given a model velocity field v( k,
x), the free parameters
k can
be determined globally by minimizing a weighted sum of residuals, e.g.
k,
x), the free parameters
k can
be determined globally by minimizing a weighted sum of residuals, e.g.
If the errors are Gaussian and Wi
The center is specified by its angular position and its distance
rlg from the LG, and the profile is characterized by
its value vlg at the LG, a core radius
rc, and a power index n. For r <<
rc the velocity rises
The toy models provide an intuitive picturing of the large-scale motions
with clues about the associated mass sources, and they can be used as
simple statistics for the comparison with theory (e.g. the bulk flow,
Section 7.1; and the GA model,
Bertschinger & Juszkiewicz
1988). However, toy modeling imposes an oversimplified
geometry associated with assumed ``sources'' on a complex
velocity field which actually arises from a continuous field of
asymmetric density fluctuations
(Section 4.5,
Section 5). Moreover, the bulk velocity statistic
computed globally suffers from a bias due to the large-scale sampling
gradients. The monopole, involving the radial
decrease of sampling density and rise of errors, has the effect of
reducing the effective volume and thus reducing the apparent conflict
between the high bulk flow and the theoretical expectations
(Kaiser 1988). The sampling dipole,
arising for example from oversampling in the
GA direction, tends to enhance the component of the bulk velocity in that
direction because it is dominated by the velocity in a smaller effective
volume (Regos & Szalay 1989;
Szalay 1988). The sampling
quadrupole arising from the Galactic zone of avoidance (ZOA) introduces
larger shot-noise into the
component parallel to the Galactic plane, which could also result in an
artificially high bulk velocity. These biases
can be partially cured by equal-volume weighting
(Section 4.2).
If the LSS evolved according to GI, then the large-scale velocity field
is expected to be irrotational, i.e.
The non-trivial step is the smoothing of the data into
u(x).
The aim in POTENT
(Dekel et al. 1990) is to
reproduce the u(x)
that would have been obtained had the true v(x) been sampled
densely and uniformly and smoothed with a spherical
Gaussian window of radius Rs. With the data as
available u(xc) is taken to be the value at
x = xc of an appropriate local velocity model
v(
TENSOR WINDOW. Unless Rs << r, the
uis cannot be averaged as scalars because the directions
xihat differ from
xchat, so u(xc) requires a
fit of a local 3D model. The original POTENT used the
simplest local model, v(x) = B, for which the
solution can be expressed explicitly in terms of a tensor window
function.
WINDOW BIAS. The tensorial correction to the spherical window has
conical symmetry, weighting more heavily objects of large
xihat · xchat. The
resultant bias of a true
infall transverse to the line of sight is a flow towards the LG, e.g.
~ 300km s-1 at the GA in the current reconstruction.
A way to reduce this bias is by generalizing B into a
linear velocity model,
v(x) = B + L
· (x-xc),
with L a symmetric tensor, which ensures
local irrotationality. The linear terms tend to ``absorb'' most of
the bias, leaving v(xc) = B less biased.
Unfortunately, a high-order model tends to
pick undesired small-scale noise. The optimal compromise is
found to be a first-order model fit out
to r = 40 h-1Mpc, smoothly changing to a zeroth-order
fit beyond 60 h-1Mpc
(Dekel et al. 1994).
SAMPLING-GRADIENT BIAS (SG). If the true velocity field is
varying within the effective window, the non-uniform sampling
introduces a bias because the smoothing is galaxy-weighted whereas
the aim is equal-volume weighting.
One should weight each object by the local volume it
``occupies'', e.g. Vi
REDUCING RANDOM ERRORS.
The ideal weighting for reducing the effect of Gaussian noise
has weights Wi
Note that POTENT could alternatively vary Rs to keep
the random errors at a
constant level, but at the expense of producing fields
not directly comparable to theoretical models of uniform smoothing.
Another way to reduce noise is to eliminate badly-observed galaxies
with large residuals
|ui - u(xi)|, where
u(xi) is obtained in a
pre-POTENT smoothing stage.
The whole smoothing procedure has been developed with the help of
carefully-designed mock catalogs ``observed'' from simulations.
ESTIMATING THE RANDOM ERRORS. The errors in the recovered
fields are assessed by Monte-Carlo simulations, where the input distances
are perturbed at random using a Gaussian of standard deviation
Several variants of POTENT are worth mentioning. The potential
integration is naturally done along radial paths using only
u(x) because the data are radial velocities, but recall
that the smoothing procedure
determines a 3D velocity using the finite effective opening angle of the
window ~ Rs / r. The transverse components are
normally determined with larger uncertainty but the non-uniform sampling may
actually cause
the minimum-error path to be non-radial, especially in regions where
Rs / r ~ 1. For example, it might be better to
reach the far side of a void along its populated periphery rather
than through its empty center.
The optimal path can be determined by a max-flow algorithm
(Simmons et al. 1994). It
turns out in practice that only
little can be gained by allowing non-radial paths because large empty
regions usually occur at large distances where the transverse components are
very noisy. Still, it is possible that the derived potential can be
somewhat improved by averaging over many paths.
The use of the opening angle to determine the transverse velocities can
be carried one step further by fitting the data
to a power-series generalizing the linear model,
where tildex = x - xc. If the
matrices are all
symmetric then the velocity model is automatically irrotational, and can
therefore be used as the final result without appealing to the potential,
and with the density being automatically approximated by
Another method of potential interest
without a preliminary smoothing step is based on wavelet analysis,
which enables a natural isolation of the structure on different scales
(Rauzy et al. 1993). The
effective smoothing involves no loss of
information and no specific scale or shape for the wavelet, and the
analysis is global and done in one step.
How successful this method will be in dealing with noisy data and its
comparison with theory and other data still remains to be seen.
A natural generalization of the toy models of
Section 4.1
is a global expansion of the fields in a discrete set of basis
functions, such as a Fourier series of the sort
with a very large number (2m) of free Fourier coefficients,
and where
This is in fact an application of the Wiener filter method (e.g.
Rybicki & Press 1992) for finding
the optimal estimator of a field
where the indices run over the data (Hoffman 1994; Stebbins 1994).
If ui = u(xi) +
The maximum-probability method has so far been applied in a
preliminary way to heterogeneous data in a box of side 200 h-1Mpc
(to eliminate periodic boundary effects) with 18 h-1Mpc resolution.
No unique density field came out as different priors
(-3
A general undesired feature of maximum probability solutions is that they tend
to be oversmoothed in regions of poor data,
relaxing to
The selection bias (Section 3.2) can be
practically eliminated from the
calibration of an inverse TF
relation,
with the model
The parameters are the inverse
TF parameters ã and
tilde b and the
An inverse method was first used by Aaronson et al. (1982b) to fit a
Virgo-centric toy model to a local sample of spirals, and attempts to
implement the inverse method to an extended sample with a general
velocity model are in progress (MFPOT by
Yahil et al. 1994).
This is a non-trivial problem of non-linear
multi-parameter minimization with several possible routes.
If the velocity model is expressed in z-space,
then ri is given explicitly by
zi but the results suffer
from oversmoothing in collapsing regions. If in r-space, then
ri
is implicit in the second equation of (18) requiring iterative minimization,
e.g. by carrying ri from one iteration to
the next one. The velocity model could be either global or
local, with the former enabling a simultaneous minimization of the
TF
and velocity parameters and the latter requiring a
sequential minimization of global
TF parameters and local velocity
parameters.
While the results are supposed to be free of Malmquist bias, they suffer
from other biases which have to be carefully diagnosed and corrected for.
The inverse method is also being generalized to account for small-scale
velocity noise
(Willick, Burstein & Tornen
1994). The Malmquist-free
results will have to be consistent with the M-corrected forward
results before one can put to rest the crucial
issue of M bias and its effect on our LSS results.
Figure 3 shows supergalactic-plane maps of the
velocity field in the
CMB frame and the associated
The velocity map shows a clear tendency for motion
from right to left, in the general direction of the LG-CMB motion
(L, B = 139°, -31° in supergalactic coordinates).
The bulk velocity within 60 h-1Mpc is 300-350 km
s-1 towards
(L, B
The GA at 12 h-1Mpc smoothing and
One can still find in the literature statements questioning the very
existence of the GA (e.g.
Rowan-Robinson 1993), which
simply reflect ambiguous
definitions for this phenomenon. A GA clearly exists in the sense that
the dominant feature in the local inferred velocity field is a coherent
convergence, centered near X
Other cosmographic issues of debate are whether there exists
a back-flow behind the GA in the CMB frame,
and whether PP and the LG are approaching
each other. These effects are detected by the current POTENT analysis
only at the 1.5
To what extent should one believe the recovery in the ZOA which is
empty of tracers? The velocities observed on the two sides
of the ZOA are used as probes of the mass in the ZOA.
The interpolation is based on the assumed irrotationality,
where the recovered transverse components enable a
reconstruction of the mass-density. However, while the SG bias can be
corrected where the width of the ZOA is smaller than the smoothing
length, the result could be severely biased where the unsampled region is
larger. With 12 h-1Mpc smoothing in Mark III the interpolation
is suspected of being severely biased
in ~ 50% of the ZOA at r = 40 h-1Mpc
(where R4 > Rs), but the
interpolation is pretty safe in the highly populated GA region, for example.
Indeed, a deep survey of optical galaxies at small Galactic latitudes
recently discovered that the ACO cluster A3627, centered at
(l, b, z) = (325°, -7°, 43 h-1Mpc), is an
extremely rich cluster (Kraan-Korteweg & Woudt 1994), very near the
central peak of the GA as predicted by POTENT, ~ (320°, 0°, 40
h-1Mpc)
(Kolatt et al. 1994).
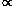
 i
Wi [ui -
xihat · v(k,
xi)]2.
i2 then L is the
likelihood, and it is a useful approximation for log-normal errors as
well. The model could first be a few-parameter ``toy'' model with simple
geometry.
Already the simplest bulk-flow model,
v(x) = B corresponding to = 0, is of interest because the
data clearly show a bulk flow component of several hundred km
s-1 in our
neighborhood (Section 7.1). Another simple
model is of spherical
symmetry, expected to be a reasonable fit in voids and in regions
dominated by one high density peak
(Bardeen et al. 1986). The
velocity profile
as a function of distance r from the infall center is not particularly
constrained by GI, and a specific profile which proved successful is
r and for r
>> rc it falls off
r-n.
The associated density profile is given in the linear
approximation by the divergence
=
-f-1 r-1 ðr
[r v (r)]. The 7S ellipticals were
modeled by a spherical infall model termed ``The Great Attractor'' (GA),
with rlg = 42 h-1Mpc toward (l, b) =
(309°, +18°),
vlg = 535km s-1, rc =
14.3 h-1Mpc, and n = 1.7 (Faber & Burstein 1988). A
similar model vaguely fits the local infall of spirals into Virgo
(Aaronson et al. 1982b).
The merged Mark II data is well fitted by a
multi-parameter hybrid consisting of a GA infall, a Virgo-centric infall,
and a ``local anomaly'' - a bulk flow shared by the ~
10 h-1Mpc-local neighborhood of 360km s-1
perpendicular to the supergalactic plane.
i
Wi [ui -
xihat · v(k,
xi)]2.
i2 then L is the
likelihood, and it is a useful approximation for log-normal errors as
well. The model could first be a few-parameter ``toy'' model with simple
geometry.
Already the simplest bulk-flow model,
v(x) = B corresponding to = 0, is of interest because the
data clearly show a bulk flow component of several hundred km
s-1 in our
neighborhood (Section 7.1). Another simple
model is of spherical
symmetry, expected to be a reasonable fit in voids and in regions
dominated by one high density peak
(Bardeen et al. 1986). The
velocity profile
as a function of distance r from the infall center is not particularly
constrained by GI, and a specific profile which proved successful is
r and for r
>> rc it falls off
r-n.
The associated density profile is given in the linear
approximation by the divergence
=
-f-1 r-1 ðr
[r v (r)]. The 7S ellipticals were
modeled by a spherical infall model termed ``The Great Attractor'' (GA),
with rlg = 42 h-1Mpc toward (l, b) =
(309°, +18°),
vlg = 535km s-1, rc =
14.3 h-1Mpc, and n = 1.7 (Faber & Burstein 1988). A
similar model vaguely fits the local infall of spirals into Virgo
(Aaronson et al. 1982b).
The merged Mark II data is well fitted by a
multi-parameter hybrid consisting of a GA infall, a Virgo-centric infall,
and a ``local anomaly'' - a bulk flow shared by the ~
10 h-1Mpc-local neighborhood of 360km s-1
perpendicular to the supergalactic plane.
4.2 Potential Analysis
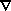 x v = 0. Any vorticity mode
would have decayed during the linear regime as the universe expanded, and,
based on Kelvin's circulation theorem, the flow remains vorticity-free in
the quasi-linear regime as long as it is laminar. Irrotationality
implies that the velocity field can be derived from a scalar potential,
v(x) = -
x v = 0. Any vorticity mode
would have decayed during the linear regime as the universe expanded, and,
based on Kelvin's circulation theorem, the flow remains vorticity-free in
the quasi-linear regime as long as it is laminar. Irrotationality
implies that the velocity field can be derived from a scalar potential,
v(x) = - (x),
so the radial velocity field
u(x) should contain enough information for a full
reconstruction. In the POTENT procedure (Bertschinger & Dekel 1989) the
potential is computed by integration along radial rays from the observer,
(x) = -
(x),
so the radial velocity field
u(x) should contain enough information for a full
reconstruction. In the POTENT procedure (Bertschinger & Dekel 1989) the
potential is computed by integration along radial rays from the observer,
(x) = -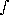 0r u(r',
0r u(r',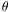 ,)dr', and the two missing
transverse velocity components are then recovered by differentiation.
Then (x) is
approximated by c
(Equation 6).
k, x - xc) obtained by
minimizing the sum (11) in terms of the parameters k within an
appropriate local window Wi =
W(xi, xc) chosen as follows.
Rn3 where Rn is the distance to
the nth neighboring object (e.g. n = 4). This procedure
is found via simulations to reduce
the SG bias in Mark III to negligible levels typically
out to 60 h-1Mpc but away from the ZOA. The
Rn(x) field can serve later as
a flag for poorly sampled regions, to be excluded from any quantitative
analysis.
i-2 but
this spoils the carefully-designed volume weighting, biasing u
towards its values at smaller ri and at nearby
clusters where the errors are small. A successful compromise is to weight
by both, i.e.,
Vi i-2
exp[-(xi-xc)2 /
2Rs2].
i
before being fed into POTENT. The error in at a grid point is
estimated by the standard deviation of the recovered over the
Monte-Carlo simulations,
(and similarly v). In
the well-sampled regions, which extend in Mark III out to
40-60 h-1Mpc, the errors are
,)dr', and the two missing
transverse velocity components are then recovered by differentiation.
Then (x) is
approximated by c
(Equation 6).
k, x - xc) obtained by
minimizing the sum (11) in terms of the parameters k within an
appropriate local window Wi =
W(xi, xc) chosen as follows.
Rn3 where Rn is the distance to
the nth neighboring object (e.g. n = 4). This procedure
is found via simulations to reduce
the SG bias in Mark III to negligible levels typically
out to 60 h-1Mpc but away from the ZOA. The
Rn(x) field can serve later as
a flag for poorly sampled regions, to be excluded from any quantitative
analysis.
i-2 but
this spoils the carefully-designed volume weighting, biasing u
towards its values at smaller ri and at nearby
clusters where the errors are small. A successful compromise is to weight
by both, i.e.,
Vi i-2
exp[-(xi-xc)2 /
2Rs2].
i
before being fed into POTENT. The error in at a grid point is
estimated by the standard deviation of the recovered over the
Monte-Carlo simulations,
(and similarly v). In
the well-sampled regions, which extend in Mark III out to
40-60 h-1Mpc, the errors are
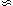 0.1-0.3, but they may blow
up in certain regions
at large distances. To exclude noisy regions, any quantitative analysis
should be limited to points where v and are
within certain limits.
c(x) =
||I - Lij|| - 1 (Equation 6). The fit must be local
because the model tends to blow up at large distances. The expansion can
be truncated at any order, limited by the tendency of the
high-order terms to pick up small-scale noise.
The smoothing here is not a separate preceding step, the
SG bias is reduced, and there is no need for numerical integration or
differentiation, but
the effective smoothing is again not straightforwardly related to
theoretical models of uniform smoothing (Blumenthal & Dekel, in preparation).
0.1-0.3, but they may blow
up in certain regions
at large distances. To exclude noisy regions, any quantitative analysis
should be limited to points where v and are
within certain limits.
c(x) =
||I - Lij|| - 1 (Equation 6). The fit must be local
because the model tends to blow up at large distances. The expansion can
be truncated at any order, limited by the tendency of the
high-order terms to pick up small-scale noise.
The smoothing here is not a separate preceding step, the
SG bias is reduced, and there is no need for numerical integration or
differentiation, but
the effective smoothing is again not straightforwardly related to
theoretical models of uniform smoothing (Blumenthal & Dekel, in preparation).
4.3 Regularized Multi-Parameter Models - Wiener
Filter
= k
[ak sin(k · x) +
bk cos(k · x)],
k k / k2
[ak cos(k · x) -
bk sin(k · x)],
and v
are related via the linear approximation (4). The maximization of the
likelihood involves a 2m x 2m matrix inversion and, even
if 2m is appropriately smaller than the number of data,
the solution will most likely follow Murphy's law and
blow up at large distances, yielding large spurious fluctuations where
the data are sparse, noisy and weakly constraining, so
the global fit requires some kind of regularization.
Kaiser & Stebbins (1991) proposed
to maximize the probability of the
parameters subject to the data and an assumed prior model
for the probability distribution of the Fourier coefficients; they assumed a
Gaussian distribution with a power spectrum
< ak2 > = <
bk2 > =
P0 kn.
(x)
which is a linear functional of another field u(x),
given noisy data ui of the latter and an assumed prior
model:
opt(x)
= < (x) ui >
< ui uj
>-1 uj,
 i with
i
independent random errors of zero mean, then the cross-correlation terms
are < (x)
u(xi) >, and the auto-correlation matrix is
< ui uj > = <
u(xi)
u(xj) > + i2 ij,
both given by the prior model.
opt is thus
determined by the model where the errors dominate,
and by the data where the errors are small.
If the assumed prior is Gaussian, the optimal estimator is also the most
probable field given the data, which is a generalization of the
conditional mean given one constraint (e.g.
Dekel 1981).
This conditional mean field can be the basis for a general algorithm
to produce constrained random realization
(Hoffman and Ribak 1991).
The same technique can also be applied to the inverse problem of
recovering the velocity from observed density. Note
(Lahav et al. 1994)
that for Gaussian fields the above procedure is
closely related to maximum-entropy reconstruction of noisy pictures
(Gull & Daniell 1978).
i with
i
independent random errors of zero mean, then the cross-correlation terms
are < (x)
u(xi) >, and the auto-correlation matrix is
< ui uj > = <
u(xi)
u(xj) > + i2 ij,
both given by the prior model.
opt is thus
determined by the model where the errors dominate,
and by the data where the errors are small.
If the assumed prior is Gaussian, the optimal estimator is also the most
probable field given the data, which is a generalization of the
conditional mean given one constraint (e.g.
Dekel 1981).
This conditional mean field can be the basis for a general algorithm
to produce constrained random realization
(Hoffman and Ribak 1991).
The same technique can also be applied to the inverse problem of
recovering the velocity from observed density. Note
(Lahav et al. 1994)
that for Gaussian fields the above procedure is
closely related to maximum-entropy reconstruction of noisy pictures
(Gull & Daniell 1978).
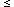 n 1) led to different fits with
similar
n 1) led to different fits with
similar  2.
This means that the data used were not of sufficient
quality to determine the fields this way and it would be
interesting to see how this method does when applied to better data.
The method still lacks a complete
error analysis, it needs to somehow deal with non-linear effects,
and it needs to correct for IM bias (perhaps as in
Section 3.2).
= 0 in the
extreme case of no data. This is unfortunate because the signal of true
density is modulated by the density and quality of sampling -
a sampling bias which replaces the SG bias. The
effectively varying smoothing length can affect any dynamical use of the
reconstructed field (e.g. deriving a gravitational acceleration from a
density field), as well as prevent a straightforward comparison
with other data or with uniformly-smoothed theoretical fields.
Yahil (1994) has recently
proposed a modified filtering method which
partly cures this problem by forcing the recovered field to have a
constant variance.
2.
This means that the data used were not of sufficient
quality to determine the fields this way and it would be
interesting to see how this method does when applied to better data.
The method still lacks a complete
error analysis, it needs to somehow deal with non-linear effects,
and it needs to correct for IM bias (perhaps as in
Section 3.2).
= 0 in the
extreme case of no data. This is unfortunate because the signal of true
density is modulated by the density and quality of sampling -
a sampling bias which replaces the SG bias. The
effectively varying smoothing length can affect any dynamical use of the
reconstructed field (e.g. deriving a gravitational acceleration from a
density field), as well as prevent a straightforward comparison
with other data or with uniformly-smoothed theoretical fields.
Yahil (1994) has recently
proposed a modified filtering method which
partly cures this problem by forcing the recovered field to have a
constant variance.
4.4 Malmquist-Free Analysis
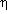 (M), as long as the
internal velocity parameter does not explicitly enter the selection process.
An inverse analysis requires assuming a parametric model
for the velocity field, v(_k,x)
(Schechter 1980). Instead of
(11), the sum is then
i
Wi [ i (observed) - i (model)]2,
given by the inverse TF
relation,
i (model) = ã +
tilde b Mi = ã + tilde b
(mi - 5 log ri),
k ,
xi).
k characterizing the velocity model.
(M), as long as the
internal velocity parameter does not explicitly enter the selection process.
An inverse analysis requires assuming a parametric model
for the velocity field, v(_k,x)
(Schechter 1980). Instead of
(11), the sum is then
i
Wi [ i (observed) - i (model)]2,
given by the inverse TF
relation,
i (model) = ã +
tilde b Mi = ã + tilde b
(mi - 5 log ri),
k ,
xi).
k characterizing the velocity model.
4.5 Fields of Velocity and Mass Density


Figure 3. The fluctuation fields of velocity and
mass-density in the Supergalactic plane as recovered by POTENT from the
Mark III velocities of
~ 3000 galaxies with 12 h-1Mpc smoothing. The vectors shown are
projections of the 3D velocity field in the CMB frame.
Distances and velocities are in 1000km s-1. Contour spacing
is 0.2 in , with the
heavy contour marking =
0 and dashed contours <
0. The LG is at the center. The GA is on the left, PP on the right, and
Coma is at the top.
The grey-scale in the contour map and the height of the surface in the
landscape map are proportional to
(Dekel et al. 1994).
c field (for  = 1) as recovered by POTENT from the preliminary Mark III
data. The data are
reliable out to ~ 60h-1Mpc in most directions
outside the Galactic plane (Y = 0), and out to ~ 70
h-1Mpc in the
direction of the GA (left-top) and Perseus-Pisces (PP, right-bottom).
Both large-scale (~ 100 h-1Mpc) and small-scale (~ 10
h-1Mpc ) features are important; e.g. the bulk velocity reflects
properties of the initial fluctuations and of the DM
(Section 7.1),
while the small-scale variations indicate the value of
(Section 8).
166°,
-20°) (Section 7.1) but the flow is
not coherent over the whole volume sampled, e.g.
there are regions in front of PP and at the back of the GA where the XY
velocity components vanish, i.e., the streaming relative to the LG
is opposite to the bulk flow direction. The velocity field shows local
convergences and divergences which indicate strong density variations on
scales about twice as large as the smoothing scale.
= 1 is a broad density peak
of maximum height = 1.4
± 0.3 located near the Galactic plane
Y = 0 at X -40 h-1Mpc. The GA extends towards Virgo near
Y 10
(the ``Local Supercluster''), towards Pavo-Indus-Telescopium (PIT) across
the Galactic plane to the south (Y < 0), and towards the Shapley
concentration behind the GA. The structure at the top
roughly coincides with the ``Great Wall'' of Coma, with
0.5. The PP peak which
dominates the right-bottom is centered near Perseus with
= 1.0 ± 0.4. PP
extends towards Aquarius in the southern
hemisphere, and connects to Cetus near the south Galactic pole, where the
``Southern Wall'' is seen in redshift surveys. Underdense regions
separate the GA and PP, extending from bottom-left to top-right. The
deepest region in the Supergalactic
plane, with = -0.7 ±
0.2, roughly coincides with the galaxy-void of Sculptor (Kauffman et
al. 1991).
-40. It is another question
whether the associated density peak has a counterpart in the galaxy
distribution or is a separate, unseen entity. The GA is ambiguous
only in the sense that the good
correlation observed between the mass density inferred from the velocities
and the galaxy density in redshift surveys is perhaps not perfect
(Section 6.2).
level in
terms of the random uncertainty.
Furthermore, the freedom in the zero-point of the distance indicators
permits adding a Hubble-like peculiar velocity
which can balance the GA back flow and make PP move away from the LG.
Thus, these issues remain debatable.
= 1) as recovered by POTENT from the preliminary Mark III
data. The data are
reliable out to ~ 60h-1Mpc in most directions
outside the Galactic plane (Y = 0), and out to ~ 70
h-1Mpc in the
direction of the GA (left-top) and Perseus-Pisces (PP, right-bottom).
Both large-scale (~ 100 h-1Mpc) and small-scale (~ 10
h-1Mpc ) features are important; e.g. the bulk velocity reflects
properties of the initial fluctuations and of the DM
(Section 7.1),
while the small-scale variations indicate the value of
(Section 8).
166°,
-20°) (Section 7.1) but the flow is
not coherent over the whole volume sampled, e.g.
there are regions in front of PP and at the back of the GA where the XY
velocity components vanish, i.e., the streaming relative to the LG
is opposite to the bulk flow direction. The velocity field shows local
convergences and divergences which indicate strong density variations on
scales about twice as large as the smoothing scale.
= 1 is a broad density peak
of maximum height = 1.4
± 0.3 located near the Galactic plane
Y = 0 at X -40 h-1Mpc. The GA extends towards Virgo near
Y 10
(the ``Local Supercluster''), towards Pavo-Indus-Telescopium (PIT) across
the Galactic plane to the south (Y < 0), and towards the Shapley
concentration behind the GA. The structure at the top
roughly coincides with the ``Great Wall'' of Coma, with
0.5. The PP peak which
dominates the right-bottom is centered near Perseus with
= 1.0 ± 0.4. PP
extends towards Aquarius in the southern
hemisphere, and connects to Cetus near the south Galactic pole, where the
``Southern Wall'' is seen in redshift surveys. Underdense regions
separate the GA and PP, extending from bottom-left to top-right. The
deepest region in the Supergalactic
plane, with = -0.7 ±
0.2, roughly coincides with the galaxy-void of Sculptor (Kauffman et
al. 1991).
-40. It is another question
whether the associated density peak has a counterpart in the galaxy
distribution or is a separate, unseen entity. The GA is ambiguous
only in the sense that the good
correlation observed between the mass density inferred from the velocities
and the galaxy density in redshift surveys is perhaps not perfect
(Section 6.2).
level in
terms of the random uncertainty.
Furthermore, the freedom in the zero-point of the distance indicators
permits adding a Hubble-like peculiar velocity
which can balance the GA back flow and make PP move away from the LG.
Thus, these issues remain debatable.