


4.5. Results
The outcome of applying VELMOD to the
A82 +
MAT
subsample described above
is presented in Figure 5. The
VELMOD likelihood curves are shown both with and without the external
quadrupole included. The formal likelihood is vastly improved when the
quadrupole is included in the fit: since the likelihood
statistic 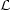 forw
is defined as -2ln[P(data|
forw
is defined as -2ln[P(data|
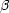 )], the
~ 20 point reduction in the minimum of
forw,
minus the 5 extra degrees of freedom when the quadrupole is modeled,
corresponds to a probability increase of a factor
~ e7.5
)], the
~ 20 point reduction in the minimum of
forw,
minus the 5 extra degrees of freedom when the quadrupole is modeled,
corresponds to a probability increase of a factor
~ e7.5  2000. The improvement in formal likelihood through the addition of the
quadrupole is so pronounced that we take the maximum likelihood value of
I
from that fit, 0.492 ± 0.068, as our best estimate. However, the
maximum likelihood estimate
of I
when the quadrupole is neglected, 0.563 ± 0.074, differs from our best
value at only the 1
2000. The improvement in formal likelihood through the addition of the
quadrupole is so pronounced that we take the maximum likelihood value of
I
from that fit, 0.492 ± 0.068, as our best estimate. However, the
maximum likelihood estimate
of I
when the quadrupole is neglected, 0.563 ± 0.074, differs from our best
value at only the 1  level. While the quadrupole is important, it does not affect qualitatively
our conclusions about the likely value
of I.
level. While the quadrupole is important, it does not affect qualitatively
our conclusions about the likely value
of I.

|
Figure 5. VELMOD likelihood statistic,
|
We can make several additional tests of
the robustness of our results. Figure 6
shows how the likelihoods per object break down for fits to different cuts
on the sample (see also Table 2).
The left-hand panel plots
forw / N
versus
I
for the A82 and
MAT samples
separately, where N = 300 for
A82 and N =
538 for MAT.
Cubic fits to the individual sample likelihoods yield
I
= 0.489 ± 0.084 and 0.498 ± 0.107 for
A82 and
MAT,
respectively. This agreement is remarkable, given
that there are only 53 galaxies in common between the two samples. Note
that
the -uncertainty
is larger for the
MAT
sample, even though it contains nearly twice as many objects as the
A82 sample. This is
because the
MAT
objects typically lie at larger distances than do
A82 objects, a property
of the likelihood fit we now illustrate.

|
Figure 6. Breakdown
of the VELMOD likelihood statistic among subsamples. The left-hand panel
plots likelihood per point vs.
|
The right-hand panel of
Figure 6 plots
forw /
N versus
I
for three subsamples in different redshift ranges. As
Table 2 shows, the agreement in
the derived values
of I
is quite good. Changing the specific redshift intervals used for this test
does not change the results significantly. Note that the
-resolution
decreases as one goes to higher redshift, despite the fact that there are
nearly equal numbers of objects in each of the three redshift bins. This is
because the likelihood is sensitive mainly to the fractional distance error
in the IRAS prediction. Hence, nearby galaxies are more diagnostic
of incorrect peculiar velocity predictions and thus
of I.
The fact
that forw /
N
decreases with redshift should not be interpreted as meaning that more
distant objects are better fit by the velocity model. Instead, this
decrease reflects a property of the VELMOD likelihood implicit in
equation (15), which shows that the expectation value
of forw /
N is ~ 1+ln
(2 ) +
ln[TF2 + (2.17
v /
[w(1 + u'(w))])2], which
increases with decreasing cz in general. This effect will be
particularly pronounced in flat zones (u' ~ -1) in
the redshift-distance relation that are found in the Local Supercluster,
which is why there is a marked difference
between forw
/ N
for the A82
and MAT
samples (the former preferentially populates the Local Supercluster region).
) +
ln[TF2 + (2.17
v /
[w(1 + u'(w))])2], which
increases with decreasing cz in general. This effect will be
particularly pronounced in flat zones (u' ~ -1) in
the redshift-distance relation that are found in the Local Supercluster,
which is why there is a marked difference
between forw
/ N
for the A82
and MAT
samples (the former preferentially populates the Local Supercluster region).
In Figure 7, we plot for the real data the same
quantities plotted for a mock catalog in Figure 3, as
well as the TF slopes. The slopes are extremely insensitive
to I.
This indicates that the IRAS assigns low and high line width
galaxies nearly the same relative distances at all
I.
Significantly, the amplitude of the fitted Local Group velocity vector is
minimized near the maximum likelihood value of
I,
just as we saw with the mock catalog. This indicates once again that the
fit attempts to compensate for a poor velocity field at very low and
high I
by moving the Local Group. The mock catalogs showed us that the errors on
the Cartesian components of wLG
are of order 50 km s-1
(Table 1). Thus, the
small value of wLG
obtained from VELMOD indicates that the
Yahil et al. (1977)
transformation to the Local Group barycenter is correct to within ~ 50
km s-1, and that the Local Group has random velocity
 50 km
s-1 relative to the mean peculiar velocity field in its
neighborhood.
50 km
s-1 relative to the mean peculiar velocity field in its
neighborhood.
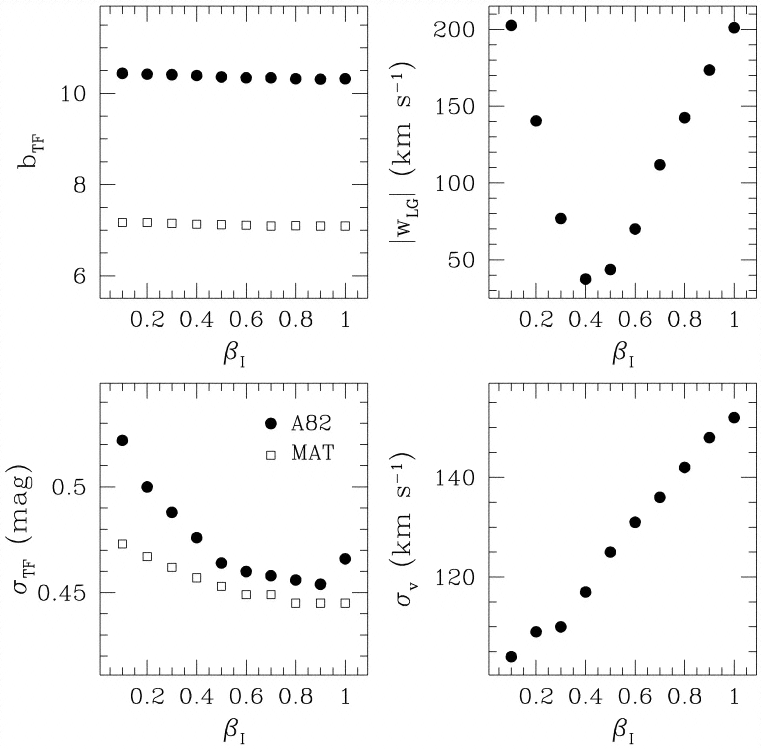
|
Figure 7. Left-hand
panels: the TF slopes (top) and scatters (bottom), for
the A82 and
MAT samples, derived
from VELMOD as a function of
|
The lower right-hand panel
of Figure 7 shows
that v
increases monotonically with
I.
Its maximum likelihood value is 125 km s-1. This is a remarkably
small number, when one considers that it includes not only the effect of
random velocity noise but also of IRAS prediction error. In
particular, if our estimate of the IRAS prediction error derived
from our mock catalog experiments
(Section 3.2), ~ 84
km s-1, is roughly correct, our value
for v
implies that the true one-dimensional velocity noise is
100
km s-1. This result is consistent with past observations that
the velocity field outside of clusters is "cold"
(cf. Sandage 1986;
Brown & Peebles 1987;
Burstein 1990;
Groth, Juszkiewicz, &
Ostriker 1989;
Strauss, Cen, &
Ostriker 1993;
Strauss, Ostriker, &
Cen 1997).
Finally, the lower left-hand panel demonstrates again what was
seen earlier with the mock catalogs
(Fig. 3), namely,
that maximizing probability does not correspond to minimizing TF scatter.
In large measure, this is because there is a trade-off between the variance
due to the velocity
noise v
and that due to the TF scatter.
As I
approaches 1, v
gets steadily
larger; TF
gets correspondingly smaller, despite the fact that the
high-I
models are worse fits to the TF data. The TF scatters level out or rise
only
at I
1.
A final test of robustness involves
eliminating the freedom in the VELMOD fit provided by the parameters
wLG
and v.
One could argue that these parameters are like the quadrupole: they
"are what they are," and
we should not allow them to absorb the fit inaccuracies at the wrong value
of I.
To assess this, we carried out two VELMOD runs in which
wLG
was assumed to vanish identically. In the first run, we fixed the value
of v
at 150 km s-1, and in the second at 250 km s-1. The
quadrupole was held fixed at its best-fit value; the free parameters in
this fit were limited to
I
and the three TF parameters for each of the two samples. The results of
this exercise are shown in Figure 8 and
in Table 2. The derived values
of I
differ inconsequentially from our best estimate obtained from the full fit.
This shows that allowing ourselves the freedom to fit both
wLG
and v
does not materially affect the derived value of
I.
The formal uncertainties
in I
are much reduced relative to the full fit because formerly free parameters
have been held fixed.
For v
= 150 km s-1, the formal likelihood is worse than for the full
fit, but only at the
~ 2
level. This reflects the fact
that v
= 150 km s-1
and wLG = 0 themselves differ by only
~ 1
from their maximum likelihood values, according to our error estimates from
Section 3.2. However, the formal
likelihood for the
v
= 250 km s-1 run is considerably worse (by a factor
of ~ 10-7)
than for the full fit. This shows that we rule out such a large
v
at high significance.

|
Figure 8. Top panel: The VELMOD
likelihood statistic
|
The bottom panel of Figure 8 shows the fitted values
of TF
as a function of
I for
each of the two values of
v
and for each of the two TF samples. The TF scatters now track the
likelihood much better than they did in the full fit (bottom panel
of Fig. 7);
with v
fixed, maximizing likelihood is more nearly equivalent to minimizing TF
scatter. However, they are still not the same thing: likelihood
maximization occurs
for I
0.5,
whereas TF scatter is minimized at
I
0.6.
This is due to the nonlocal nature of the probability distribution
described by equation (11) (cf.
Fig. 1). The likelihood of a
given data point depends on the peculiar velocity and density fields all
along the line-of-sight interval allowed by the TF and velocity dispersion
probability factors, not merely on how close the TF-inferred and
IRAS-predicted distances are to one another.
The bottom panel of
Figure 8 also shows that the TF scatter one
derives from VELMOD depends on the value of
v.
The full fit shows us that IRAS errors plus true velocity noise
amount to ~ 125 km s-1. The values of
TF
obtained in the full fit (Table 2)
absorbed the remaining variance. Changing
v
to 150 km s-1 reduces the TF scatters by about 0.01 mag.
With v
fixed at 250 km s-1, however, we find 0.39 and 0.40 mag for the
A82 and
MAT TF scatters,
respectively. While these latter values are certainly underestimates, the
large changes demonstrate that it is very difficult to
estimate TF
to high accuracy because of its covariance, however slight, with velocity
noise. This is one reason that it is inadvisable to use the value of
TF
obtained from fitting TF data to peculiar velocity models as a measure of
the goodness of fit. We return to this issue in
Section 5.