


As we have demonstrated above, there are many scaling laws, which connect cosmological observables. The main reasons for that are the scale-free nature of gravitation and the (hopefully) scale-free initial perturbations.
The gravity scaling could, in principle, extend into very small scales, if we had only dark matter in the universe. In the real world the existence of baryons limits the scaling range from below by typical galaxy masses.
The scaling range starts from satellite galaxy distances, several tens of kpc, and it may extend up to cluster sizes, 10 Mpc; two-three decades is a considerable range. The scaling laws at supercluster distances and larger are determined by the physics of initial fluctuations.
The first scaling law characterizing the distribution of galaxies is
the power-law behavior of the two-point correlation function at
small scales:
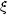 (r)
(r)
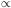 r-
r-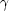 . Other authors try to fit the quantity 1 +
(r) to a
power law
rD2-3.
Obviously the previous two power laws can only hold simultaneously
within the strong clustering regime, where
(r)
>> 1 and, therefore - only at those scales - the equality
= 3 -
D2 holds. At intermediate scales (3 < r <
20 h-1 Mpc) the correlation dimension
D2 is ~ 2, increasing at larger scales up to
D2
. Other authors try to fit the quantity 1 +
(r) to a
power law
rD2-3.
Obviously the previous two power laws can only hold simultaneously
within the strong clustering regime, where
(r)
>> 1 and, therefore - only at those scales - the equality
= 3 -
D2 holds. At intermediate scales (3 < r <
20 h-1 Mpc) the correlation dimension
D2 is ~ 2, increasing at larger scales up to
D2 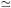 3,
indicating an unambiguous transition to
homogeneity. Moreover the statistical analysis of the galaxy
catalogs permits to conclude that, within the fractal regime, the
scaling is better described in terms of multifractal inhomogeneous
measures rather than using homogeneous self-similar scaling laws.
3,
indicating an unambiguous transition to
homogeneity. Moreover the statistical analysis of the galaxy
catalogs permits to conclude that, within the fractal regime, the
scaling is better described in terms of multifractal inhomogeneous
measures rather than using homogeneous self-similar scaling laws.
Scaling of the galaxy correlation length r0 with the
sample size,
r0
Rs, is a strong prediction for a fractal
distribution. Nevertheless, this behavior is clearly ruled out by
the present available redshift catalogs of galaxies. The scaling of
r0 for different kind of objects - from galaxies to
clusters including clusters with different richness- has been expressed
as a linear dependence of r0 with the intercluster
distance dc.
This law, however, does not hold for large values of dc.
One successful scaling law found in the distribution of galaxies is the scaling of the angular two-point correlation function with the sample depth. In this case however, the scaling argues against an unbounded fractal view of the distribution of galaxies, supporting large-scale homogeneity.
Finally, the hierarchical scaling hypothesis of the q-order correlation function needs further confirmation from the still under construction deep and wide redshift surveys.
We have attempted here to provide an overview of the mathematical and statistical techniques that might be used to characterize the large scale structure of the universe in coordinate space, velocity space, or both, with, we hope, enough reference to actual applications and results to indicate the power of the various techniques and where they are likely to fail. Of these methods, the ones that have been used most often and so are needed for reading the current literature are the two-point correlation function (Sect. V.B), the power spectrum (Sect. VI.C), counts-in-cells and the void probability function (Sect. VI.E.3), and fractal and multifractal measures (Sect. VI.E.4). Those that we believe have the most potential for the future analysis of the very large redshift data bases currently becoming available are the Fourier methods (Sect. VI.C and Sect. VI.D), although surely the reliable determination of the two-point correlation function at large scales is still very important for understanding the large-scale structute (Durrer et al., 2003).
Most of the techniques can be applied equally well to real data (in two or three dimensions) or to the results of numerical simulations of how structure ought to form in universes with various cosmological parameters, kinds of dark matter, and so forth (also in three dimensions or two-dimensional projections).